Check out the conversation on Apple, Spotify, and YouTube.
Brought to you by:
Kameleoon: Leading AI experimentation platform
Testkube: Leading test orchestration platform
Pendo: The #1 software experience management platform
Bolt: Ship AI-powered products 10x faster
Product Faculty: Get $550 off their #1 AI PM Certification with my link
Today’s episode
I have done four eval episodes now. We covered error analysis and LLM judges with Hamel and Shreya. Evals from first principles with Ankit. The PM’s role in depth.
But I kept hearing the same question: how do I actually build one from scratch?
That is what today’s episode delivers. We build an eval entirely from scratch. Live. On camera. No pre-written prompts, no pre-written data.
I sat down with Ankur Goyal, Founder and CEO of Braintrust, the eval platform behind Replit, Vercel, Airtable, Ramp, Zapier, and Notion. They just announced their Series B at an $800 million valuation.
Users are running 10x more evals than this time last year. People log more data per day now than they did in the entire first year the product existed. The episode explains why, and then we build one live.
We connect to Linear’s MCP server, generate test data, write a scoring function, and iterate until the score goes from 0 to 0.75. And along the way, Ankur drops what might be the most important reframe of the year: evals are the new PRD.
Plus, we cover the complete eval playbook for PMs:
If you want access to my AI tool stack - Dovetail, Arize, Linear, Descript, Reforge Build, DeepSky, Relay.app, Magic Patterns, Speechify, and Mobbin - grab Aakash’s bundle.
If you want my coaching in your job search, apply to my cohort.
Newsletter deep dive
I took everything from the episode and combined it with lessons from four eval deep dives. Here is the complete practitioner’s playbook:
Why vibe checks stop scaling
The data-task-scores framework
Evals are the new PRD
Offline vs online evals
How to maintain eval culture
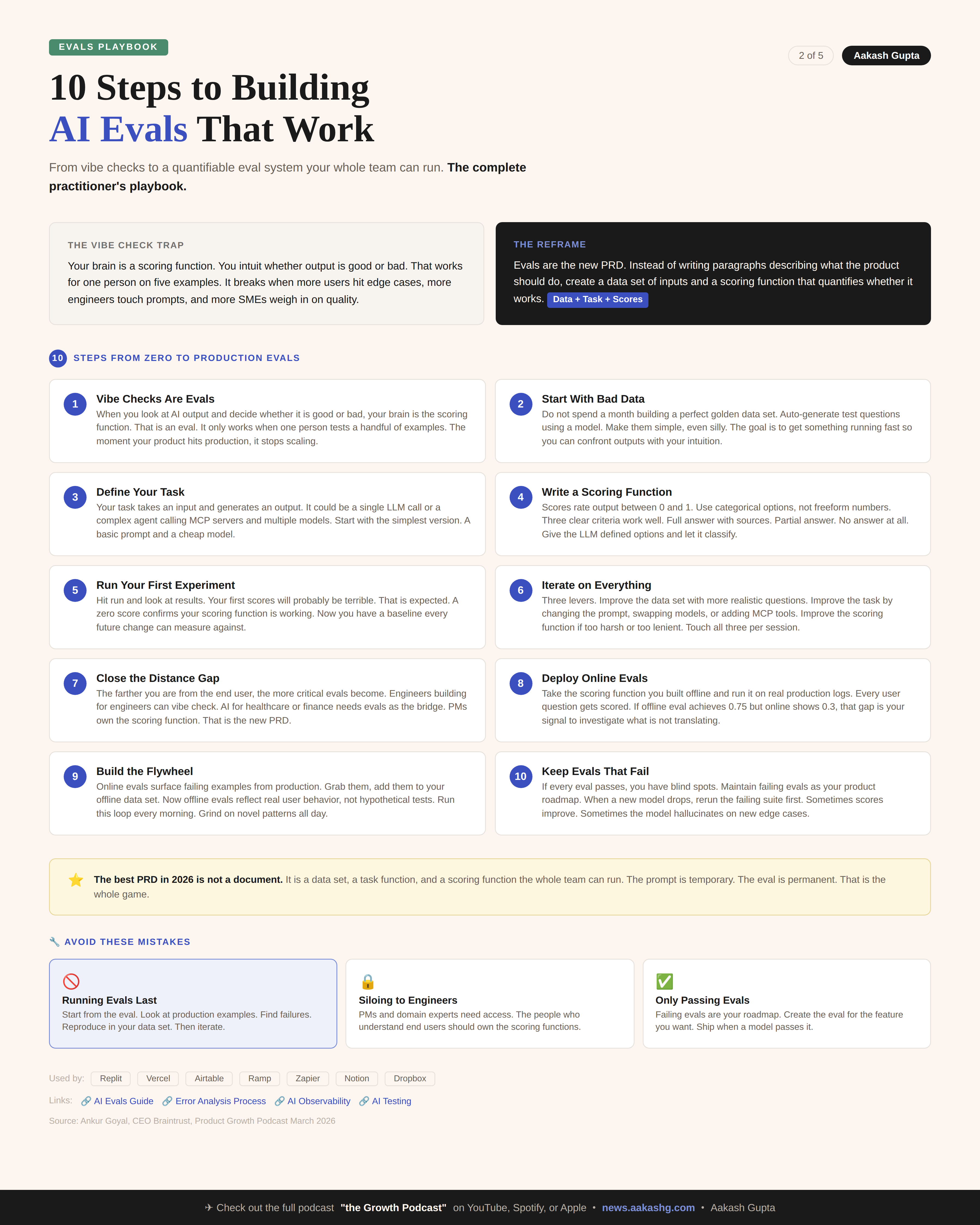
1. Why vibe checks stop scaling
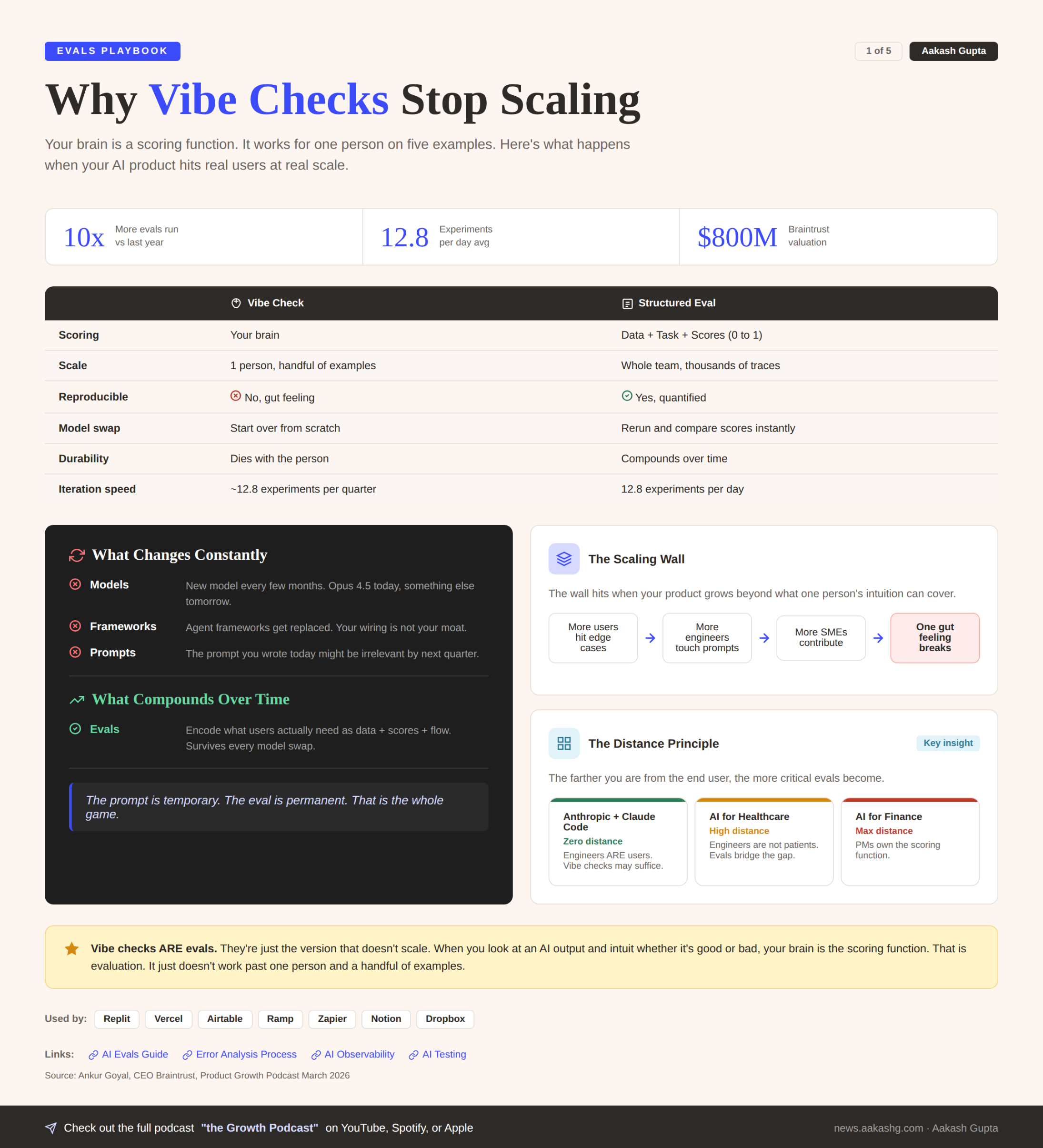
Open your AI product right now. Try three examples. Tweak the prompt. Ship it.
Two weeks later, support tickets start coming in about edge cases you never tested.
That is the vibe check trap.
When you do a vibe check, you are using your brain as a scoring function. You intuit whether the result is good or bad. That is an eval. It is just the version that does not scale.
Vibe checking is not wrong.
It is the earliest version of what eventually needs to become structured. In the error analysis process I covered in an earlier episode, the first step is reviewing 100 traces and taking notes. That is a structured vibe check.
Here is what matters: the best companies treat the transition from vibe checks to structured evals as a product decision, not an engineering one.
The wall hits when more people start using the product, more subject matter experts start contributing to quality, and more engineers start touching the prompts.
At that point, one person’s gut feeling cannot cover the surface area. You need software and process to execute at scale with predictable performance.
And here is the thing about durability. Models change every few months. Agent frameworks get replaced.
The prompt you wrote today might be irrelevant by summer. But if you invest in understanding what your users actually need and encode that as data, scores, and eval flows, that survives every model swap.
The companies that believe their agent wiring is their moat are highly likely to fail. The ones building true differentiation are the ones investing in evals.
The prompt is temporary. The eval is permanent. That is the whole game.
2. The data-task-scores framework
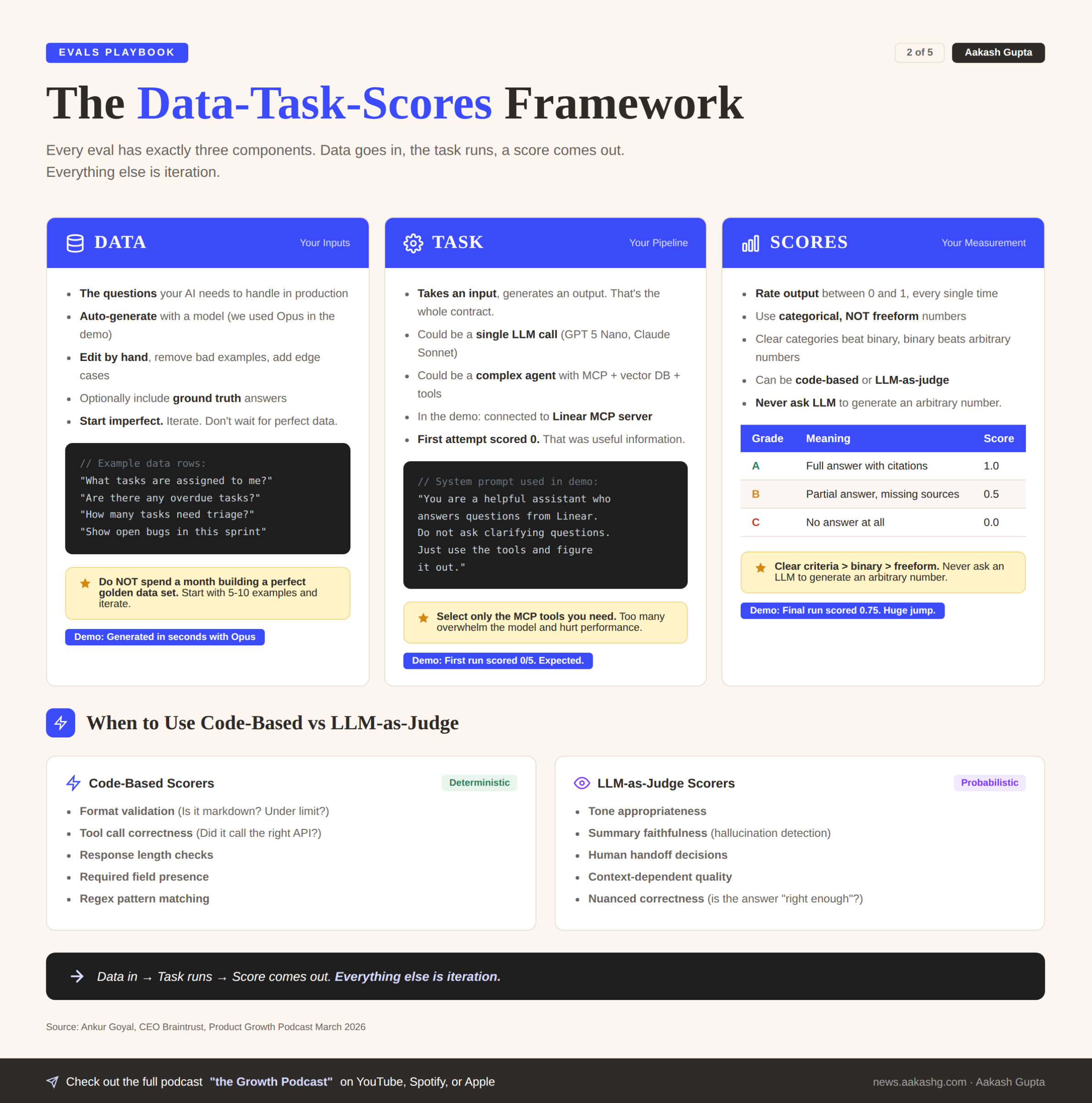
In the evals deep dive, we covered the full analyze-measure-improve lifecycle. That is the theory. Here is the practitioner’s shorthand: every eval, no matter how complex, is exactly three things.
Component 1 - Data
A set of inputs your AI product needs to handle.
During the episode, we generated test data for a Linear task management bot:
“What tasks are assigned to me?”
“Are there any overdue tasks?”
“How many tasks need to be triaged?”
You can optionally include ground truth answers. If you know the correct answer is 12, include it. If you do not, skip it.
Do not spend a month building a perfect golden data set before running your first eval. Auto-generate silly questions. Jump in. Start iterating.
This echoes what I covered on bootstrapping datasets with synthetic data. But in the live demo, we took it further. We used Opus to generate the data set in seconds, edited it by hand, and ran our first eval within minutes.
Component 2 - Task
A task takes an input and generates an output. It could be:
A single LLM call to GPT 5 Nano
A complex agent calling MCP servers, vector databases, and multiple models
Anything in between
At the end of the day, it produces some kind of output. That is what you evaluate.
During the demo, the first task attempt failed badly. The model just said “Happy to help with Linear” instead of answering. That zero score was expected and useful.
Here is what happened next.
We connected the Linear MCP server so the model actually had access to task data. Still failed. The model said “I am ready to help with Linear tasks” but never called a single tool.
So we changed the system prompt:
Don’t ask clarifying questions, just use the tools and figure it out.This matters more than you’d expect. Models are post-trained to ask clarifying questions in conversational contexts. In an eval pipeline where you send one question and expect one answer, that post-training behavior works against you. You have to explicitly override it.
Then we loosened the scoring function. It was penalizing responses that referenced Braintrust tasks as sources, even though that was valid citation behavior. The scorer was too harsh for what we actually cared about.
Then we added few-shot examples to the prompt and specified which MCP tools to use.
Score went from 0 to 0.75 across the board. Each iteration touched a different part of the data-task-scores framework. That is the rhythm: identify which component is the bottleneck, fix it, rerun.
Component 3 - Scores
Scores take the input, the expected output if you have one, and the actual output. Their job: produce a number between 0 and 1.
That normalization is critical. It forces everything to be comparable. A week from now, when you run a new eval after swapping the model, you compare directly against today.
Do not overcomplicate scores. Use categorical options, not freeform numbers:
A = Full answer with citations
B = Partial answer
C = No answer at all
In the evals deep dive, I recommended binary Pass/Fail as the default. There is a case that not every score must be binary, but clear criteria beats freeform every time. The key is that you are not asking the LLM to generate an arbitrary number. You are giving it defined options and asking it to classify.
Data in, task runs, score comes out. Everything else is iteration.
3. Evals are the new PRD

This is the reframe that hit me hardest.
Think about a PRD from 2015. Unstructured document. A spec meant to communicate how to build something. The engineering team reads it, half follows it, the final product never matches.
The modern PRD is an eval. It is something that an engineering team who maybe does not know everything about the problem can use to quantify how well the software is solving it.
Step 1 - Encode your product intuition as data
Instead of writing paragraphs describing what the product should do, create a data set of inputs that represent what users actually need.
Step 2 - Use scores as success criteria
Instead of prose acceptance criteria, write scoring functions that quantify whether the software works.
An engineering team that does not know the domain can look at the eval and know exactly what good looks like.
When the eval passes and the product still feels wrong, that is on you. Your scoring function does not capture what matters. And that is actually a new area of leverage that PMs did not have before. You go from providing a qualitative spec nobody follows into something quantifiable.
I have been saying PMs should own error analysis for months now. This episode pushed that further: PMs should own the eval itself. The scoring function IS the modern PRD.
Step 3 - Close the distance gap
The farther you are from the end user, the more critical evals become.
Ankur framed this as a distance principle.
At Anthropic, the people training the models, building the harness, building the product, and using the product all sit inside one set of walls. Feedback circulates with almost no friction. In healthcare, engineers are not patients or doctors.
Ankur’s parents are both doctors, and he said when he talks to them about their work, he has almost no idea what they’re talking about. The jargon is specialized, the stakes are high, and the engineering team has no intuition for what matters.
Evals become the mechanism that bridges that gap.
Finance has the same problem with different jargon. Domain experts speak a language that engineers don’t, and patients become counterparties, but the structural issue is identical. PMs own the scoring function that translates between what users need and what engineering measures.
There was a Twitter controversy about Claude Code not using evals. This blew up enough that someone pinged me about it the day it happened because their boss was questioning whether evals even mattered.
Here is the reality: Claude Code is doing evals. People at Anthropic are using the product, providing feedback, and incorporating that feedback into iterations. That is a form of eval. They just don’t need formal process because the distance between builder and user is zero. That is not the case for 99% of AI products.
One more thing Ankur pointed out: a big use case for Braintrust has been helping companies collect evals they can share with labs so the labs can better support their use case.
When you have distance, you need a ledger to capture the information. Otherwise, how do you communicate it?
The best PRD in 2026 is not a document. It is a data set, a task function, and a scoring function the whole team can run.
4. Offline vs online evals
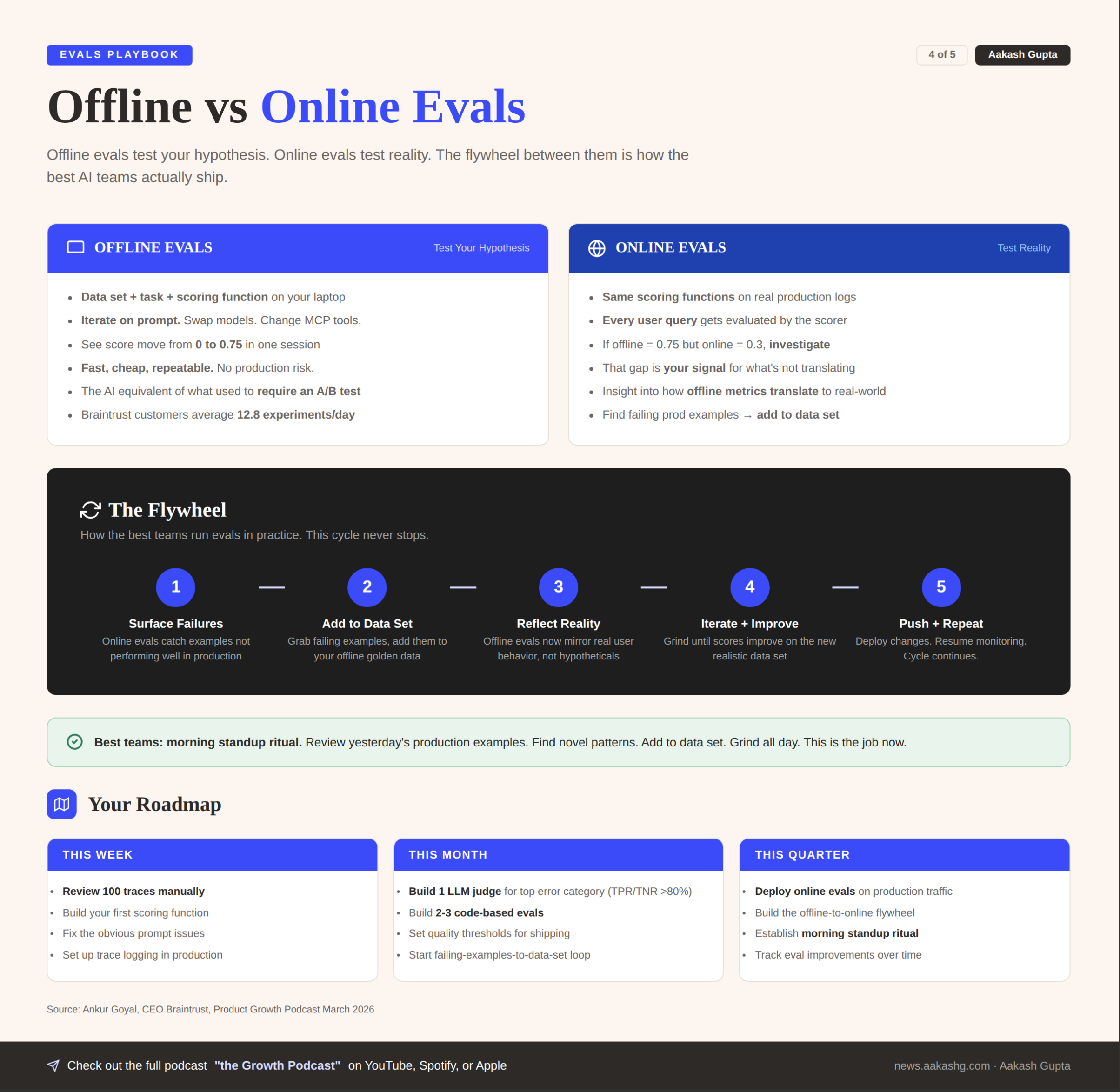
You have your eval running in a playground. Scores are improving.
That is only half the picture.
Workflow 1 - Offline evals test your hypothesis
This is what we built in the demo. A data set, a task, a scoring function. You run experiments on your laptop. You iterate on the prompt. You swap models. You see the score move from 0 to 0.75.
Fast. Cheap. Repeatable.
This is the AI equivalent of what used to require an A/B test. In the old world, non-deterministic problems meant expensive production experiments. Now you can run those experiments offline. That is why Braintrust customers average 12.8 experiments per day.
Workflow 2 - Online evals test reality
Take the same scoring functions and run them on real production logs. Every time a user asks a question, the scorer evaluates the response.
If your offline eval achieves 0.75 but your online eval consistently shows 0.3, something is not translating.
Workflow 3 - The flywheel
The real power is in the loop:
Online evals surface examples not performing well in production
Grab those examples, add them to your offline data set
Your offline evals now reflect real user behavior, not hypothetical test cases
Iterate until scores improve
Push changes, repeat
This is the same continuous improvement flywheel I covered in the evals deep dive. Now you can see what it looks like in practice at companies like Ramp, Notion, and Dropbox.
The best teams run this loop daily. More on the specific ritual in the eval culture section below.
Offline evals tell you what should work. Online evals tell you what actually does. The gap between them is your roadmap.
5. How to maintain eval culture

The biggest risk is not that your eval system is bad. It is that your team treats evals as a gate instead of an iterative loop.
Mistake 1 - Running evals only at the end
If you edit your prompt, test it on three examples, then run a full eval just to see if you can ship, you are doing it backwards.
Start from the eval. The best teams Ankur works with have a morning ritual. In standup, they pull up examples from the previous day’s production logs. They reconcile what they see with what their eval scores show. They find novel patterns that have emerged, add them to the data set, and grind on those failures all day. That is the job now.
Mistake 2 - Only having evals that pass
If every eval succeeds, you have blind spots. Either:
You do not understand what your users are hitting
You do not understand what is impossible today
Have failing evals. When a new model drops, rerun them first. Something interesting always happens.
And interesting does not always mean better. Gemini 3 Flash was outperforming Gemini 3 Pro on coding benchmarks but hallucinating more. Those nuances only surface with a full testing suite.
This is also how you plan product launches around model releases.
Braintrust shipped Loop this way. They built the eval for the feature before they shipped it. The eval failed on every model they tried. Then Claude 3.7 came out and there was a huge jump. The eval passed. They shipped.
Ankur said there was a watershed moment where 3.7 was the first model that could look at its own work and improve. Prior to that, he said models were like a dog looking at itself in the mirror. They didn’t recognize they were evaluating a virtual representation of themselves.
Create the eval for the feature you want. Watch the models. The moment a model hits the quality threshold, you ship.
Mistake 3 - Siloing evals to AI engineers
Evals should not be constrained to engineers. Product managers need access. Domain experts need access. The people who understand the end user should be improving the scoring functions.
Zapier was Braintrust’s first customer. Ankur told a story about their CTO Brian, who has been there for a long time and is very successful.
When Ankur met him, Brian introduced himself as a full-time AI engineer. This guy probably doesn’t have to work, but Ankur said he has never seen anyone nerd out about AI as much as Brian does. Companies like Zapier have pre-existing product-market fit.
If Ramp doesn’t work, it is very bad. They don’t have the leeway to screw things up. The quality bar is high, the scale is real, and vibe checks can’t cover the surface area. That is why these companies gravitate toward evals.
Braintrust removed user-based pricing specifically for this reason. They realized evals should not be locked behind engineering seat licenses.
Going back to the PRD analogy: if only engineers can see and edit the PRD, the product reflects what engineers think matters. Not what users need.
The teams that win are not the ones with the most sophisticated eval setup. They are the ones where evals are the first thing the PM opens every morning.
The whole game
Treat the eval as a first-class product artifact with a PM who owns the experience. The scoring function is the new PRD. The data set is the new user research. The flywheel is the new sprint cycle.
Open your platform of choice, write your first scorer, and run it on 5 real examples today. You will learn more in that first hour than in a month of vibe checking.
The prompt is temporary. The eval is permanent. That is the whole game.
Where to find Ankur Goyal
Related content
Newsletters:
Podcasts:
PS. Please subscribe on YouTube and follow on Apple & Spotify. It helps!