Check it out on Apple, Spotify, or YouTube.
Brought to you by:
The AI Evals Course for PMs & Engineers: You get $800 with this link
Jira Product Discovery: Plan with purpose, ship with confidence
Vanta: Automate compliance, Get $1,000 with my link
AI PM Certification: Get $500 with code AAKASH25
Today’s Podcast
Today, we’ve got two of the world’s leading experts on AI evals: Hamel Husain and Shreya Shankar.
You’ll learn:
Why AI evaluations are the most critical skill for building successful AI products
How to effectively "hill climb" towards better AI performance
How they built a highly successful course ($900K/ cohort)
If you're building AI features, or aiming to be a better PM, this episode is for you.
Your Newsletter Bonus:
For being a newsletter subscriber, we also put together a specific post just for you.
The PM’s Role in AI Evals: Step-by-Step
As product managers, we’re comfortable with user stories and roadmaps, but the idea of "evaluating AI" sounds like something reserved for the engineering team.
For too long, we've been treating AI development like traditional software projects, where we hand off requirements to engineering and wait for a finished product. This is a recipe for failure.
Engineers, as brilliant as they are, often lack the deep domain and user context to judge whether an AI's output is truly "good."
The result? We get AI products that are technically functional but miss the mark on user needs, leading to a trust deficit that can derail adoption before it even begins.
Product Managers are the most important people to drive AI evaluation.
Today’s Post
Last month, we covered the all purpose beginner’s guide to Evals. That’s the full engineering guide. Today, we go into a 201 topic: the PM-specific guide for Evals.
Why Evals are a PM Responsibility
The PM’s Playbook for Leading AI Evals
Connecting Evals to Impact
Part 1: Why Evals are a Product—Not Just Engineering—Responsibility
The single biggest challenge in AI products isn't the technology; it's trust.
If your users don't trust your AI to be helpful and reliable, they won't use it.
If your stakeholders don't trust your metrics, they won't invest.
This is the trust deficit, and as a PM, it's your primary job to solve it.
For a long time, we've relied on anecdotes or "vibe checks" to gauge AI quality. We'd look at a few outputs and say, "Yeah, that feels about right."
But that's not a strategy; it's hope.
Evals are the language of trust. They are the only way to systematically prove that your AI is improving.
The first step is to shift the conversation from subjective feelings to objective facts.
Instead of asking your team, "Does this response feel helpful?", you need to start asking, "Did the AI correctly use the user's stated budget in its property search? Yes/No."
This simple change is the foundation of a data-driven culture.
The Pitfalls of Off-The-Shelf
This is where many teams, including my own in the past, have made a critical mistake. We see a vendor offering an off-the-shelf "LLM as a Judge" for things like "helpfulness" or "faithfulness," and we plug it in.
It's tempting because it feels easy.
But, this is incredibly dangerous because one-size-fits-all metrics are vanity metrics.
An off-the-shelf judge has no idea what "helpful" means for your specific users.
Is a helpful response concise? Does it include links?
For an investor persona, a "helpful" response is data-driven; for a first-time homebuyer, it's reassuring and avoids jargon.
Using a generic judge is like using a generic customer satisfaction score to measure the success of a highly specialized surgical tool. The metric might look good on a dashboard, but it's measuring the wrong thing.
You have to measure your evaluator. You must align your automated judge with your goals and prove that its judgments match those of a human expert—you.
And that's the final piece of the puzzle: as the Product Manager, you are the principal domain expert.
Your first step isn't to build a dashboard; it's to block 30 minutes on your calendar, pull 10 real user interactions, and write down what went right and what went wrong.
That single habit will give you more insight than any off-the-shelf tool.
Outsourcing this judgment to engineering is a grave mistake. Trying to manage AI projects like traditional software will, as Hamel says, "lead to failure. Guaranteed."
Part 2: The PM's Playbook for Leading AI Evals
So, how do you step into this role? It starts by reclaiming your direct line of communication with the AI and then systematically analyzing its behavior.
Here's the playbook:

Step 1 - Direct Prompting
For decades, getting a computer to do what you want required an engineer to translate your ideas into code. That's no longer true.
LLMs have given product managers a superpower: the ability to communicate your intentions, taste, and judgment directly to the computer in English. This is your most direct lever for influencing AI behavior.
Too many organizations make the grave mistake of putting an engineering team between the PM and the prompt. This creates a painful game of telephone where your insights get lost in translation. As a PM, you need to be in the driver's seat.
Here's your actionable step: don't just file tickets with vague requests like "make the response more empathetic."
Ask your engineering team for an "Integrated Prompt Environment." This doesn't have to be a massive platform; it can be a simple internal web app where you can tweak a prompt and see the output immediately.
Start by changing one sentence in a prompt and observing the impact on 10 test cases.
You'll be amazed at how much you learn.
Step 2 - Error Analysis
But writing a good prompt is only the beginning. Great prompts are born from data. You have to systematically analyze the AI's outputs to understand where to focus your efforts.
Here's an actionable method, Error Analysis. It's a structured process with roots in social sciences (Grounded Theory) that transforms unstructured feedback into a prioritized list of problems.
Open Coding: For 20-50 user interactions, just write down notes on what went wrong. Don't worry about categories yet. Your note might be as simple as, "AI suggested a showing on a day the agent is unavailable." or "The tone here was too casual for an investor client."
Axial Coding: After you've collected your notes, group them into themes. The notes about unavailable days and incorrect showing times all fall under a broader category you might call "Scheduling Conflict."
This process is like doing user research, but your user is the model itself. In a few hours, you'll have a data-backed, prioritized list of the most important issues to tackle.
Step 3 - LLM-as-a-Judge
Once you understand your failure modes, you face a new problem: you can't manually review every single output.
This is where you can use a second LLM to automate your judgments, a technique often called LLM-as-a-Judge.
But this raises an obvious question: how can you trust one LLM to grade another? Isn't that just trading one black box for another?
Here's the actionable answer: You don't trust it. You verify it.
You create a "gold standard" set of ~100 examples that you have personally labeled pass/fail. Then, you measure your automated judge's performance against your labels, calculating its True Positive Rate (how often it correctly identifies a pass) and True Negative Rate (how often it correctly identifies a fail).
Only when the judge agrees with your expert judgment more than 90% of the time can you trust its metrics to evaluate your AI at scale.
This gives you the confidence to trust your automated metrics, and more importantly, it gives you the data to prove to your organization that you are making real, measurable progress in improving the quality of your AI product.
Part 3: Connecting Evals to Impact
Building a suite of trustworthy evals is a huge step, but it's not the final one.
The ultimate goal is to create an AI product that users love and that drives business results. This is where we connect our carefully crafted offline metrics to the messy reality of the real world.
One of the biggest advantages of having reliable, automated evals is the speed of the feedback loop.
Instead of waiting weeks for A/B test results to trickle in, you get an immediate signal on quality every time you change a prompt or tune a model.
When your team suggests a new prompt, you can run your eval suite and know in minutes if the change introduced a regression, like causing the AI to ignore budget constraints.
This creates a rapid "Analyze-Measure-Improve" cycle that is simply impossible with traditional product metrics alone.
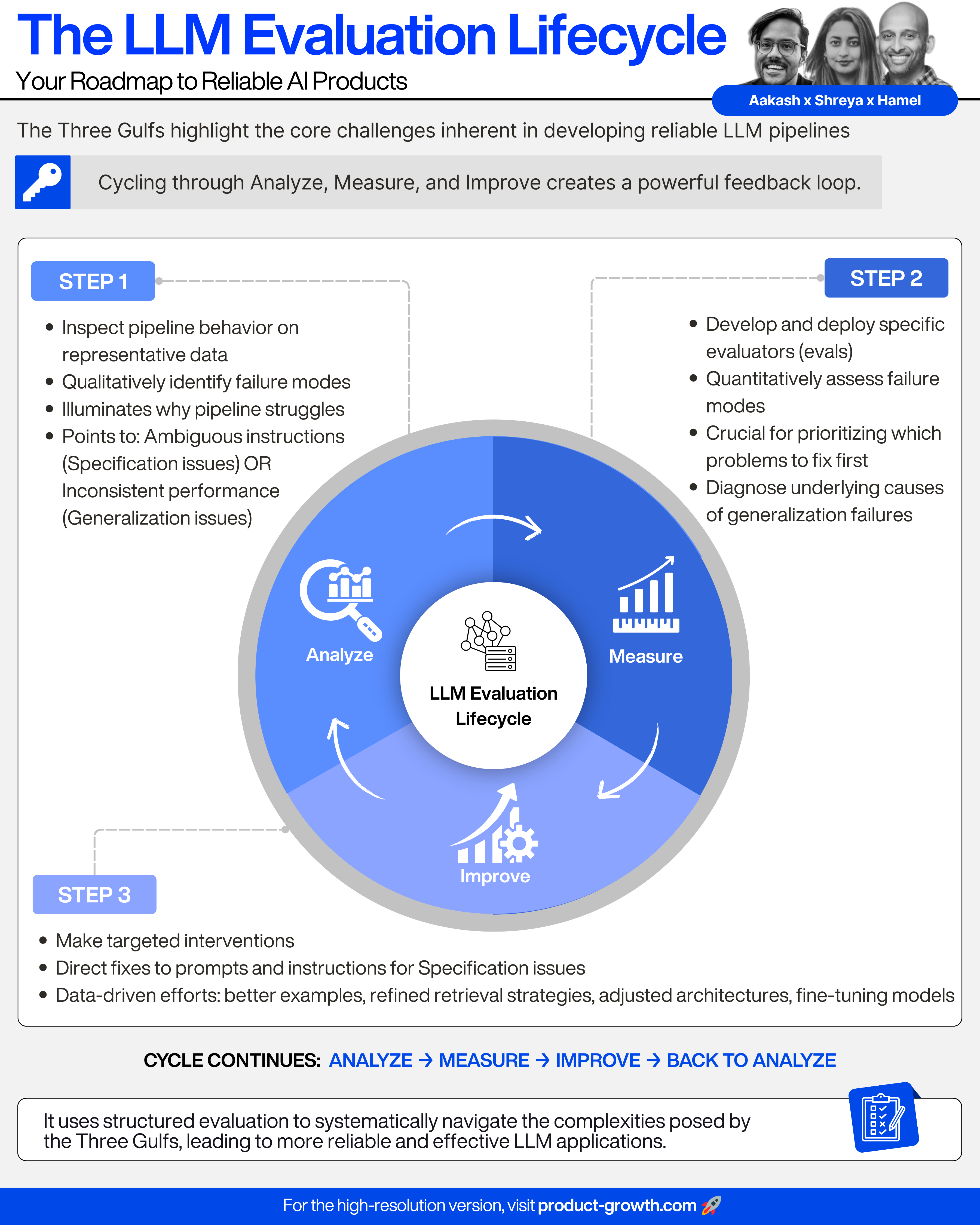
However, offline metrics are a proxy for user happiness, and you must prove they are a good proxy.
Actionable Method: Once a month, correlate your key offline eval scores with your online business metrics.
For example, create a simple scatter plot: does a 10% improvement in your "scheduling success" eval correlate with a 5% increase in actual tour bookings? If not, your eval isn't measuring what truly matters to users.
When your offline evals are improving but your user-facing metrics are flat or declining, it's a clear signal to go back to error analysis. Imagine your team celebrates a 30% reduction in "hallucinated property features," but an A/B test shows no change in user engagement.
A fresh round of error analysis on real user sessions might reveal the true problem: the AI is too verbose, and users are dropping off before they even see the property details. This insight tells you to build a new, more relevant eval for "conciseness."
This validation process creates a powerful, virtuous cycle:
You define what "good" looks like based on deep user understanding.
You build offline evals to measure that definition at scale.
You use those evals to rapidly iterate and improve your AI.
You validate that your improvements are translating to real-world impact with user feedback and A/B tests.
You refine your evals based on what you learn.
This is how you build a truly data-driven culture for AI development. It's grounded in metrics that your entire organization can trust because you, the PM, have vetted them and proven they correlate with real-world success.
You're in the Driver's Seat
As a Product Manager, it's easy to feel like a passenger in the AI development process, intermediated by engineers and complex technology. But the truth is, you are in the driver's seat.
You possess the single most important asset for building high-quality AI: a deep understanding of your users and what "good" truly means.
You don't need to be an engineer to lead on evaluation. You have the domain expertise and user-centric vision that is essential for defining what success looks like.
This is your unfair advantage.
If you’ve read this far, I’m sure you’ll LOVE this episode :)
Key Takeaways

Where To Find Them
LinkedIn:
Hamel: Hamel’s LinkedIn
Shreya: Shreya’s LinkedIn
AI Evals Course: World’s best AI Evals Course (You get $800 off with this link)
If you prefer to only get newsletter emails, unsubscribe from podcast emails here.
If you want to advertise, email productgrowthppp at gmail.
Related
Podcasts:
Newsletters:
P.S. More than 85% of you aren't subscribed yet. If you can subscribe on YouTube, follow on Apple & Spotify, my commitment to you is that we'll continue making this content better.