Check out the conversation on Apple, Spotify, and YouTube.
Brought to you by
Product Faculty: Get $550 off their #1 AI PM Certification with my link
Amplitude: The market-leader in product analytics
Pendo: The #1 software experience management platform
NayaOne: Airgapped cloud-agnostic sandbox
Kameleoon: Leading AI experimentation platform
Today’s episode
There’s very few AI PMs who have seen inside a single company like Netflix, Meta, or Amazon. It’s even more rare to find one who has experience at all three.
That’s who I’ve brought in today.
Jyothi Nookula breaks out the whiteboard for a full deep dive covering all aspects of AI PM fundamentals and job searching for an AI PM job.
If you are trying to break into AI PM, this is the one episode to watch.
If you want access to my AI tool stack - Dovetail, Arize, Linear, Descript, Reforge Build, DeepSky, Relay.app, Magic Patterns, Speechify, and Mobbin - grab Aakash’s bundle.
I’m putting on a free webinar on Behavioral and AI PM interviews. Join me.
Newsletter deep dive
As a thank you for having me in your inbox, here is the complete guide to becoming an AI product manager in 2026.
Taxonomy of AI PM Roles
The Core AI PM fundamentals
When to use AI
Which AI to Use When
The 3 Building Blocks of an AI Feature
How to Become an AI PM
1. Taxonomy of AI PM Roles
Before you write a resume, update a portfolio, or prep for a single interview, you need to answer two questions.
What type of AI PM role are you targeting? And where in the stack do you want to sit?
Get these wrong and you’ll spend months preparing for interviews that test completely different skills than what you studied.
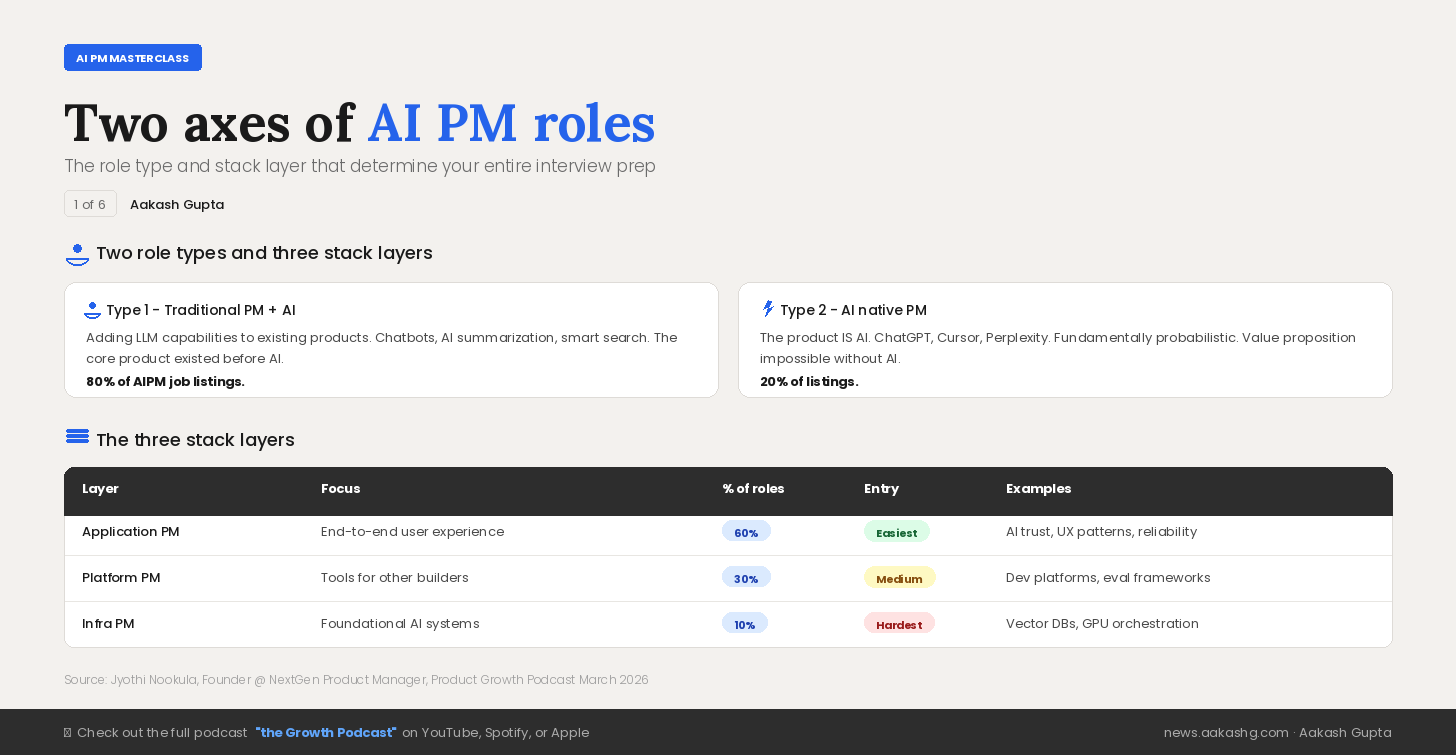
Axis One - Traditional PM with AI features vs AI Native PM
Type 1 - Traditional PM with AI features
This is 80% of what is labelled as AI PM jobs right now. Companies adding LLM capabilities to existing products.
A chatbot on a customer service portal
AI summarization inside a document tool
Smart search on an existing knowledge base
The core product existed before anyone bolted an LLM onto it.
Type 2 - AI native PM
The remaining 20%. Here the product IS AI.
The product is fundamentally probabilistic. The value proposition is impossible without AI. You cannot build ChatGPT without an LLM.
There are 4x more open roles in the traditional category. If you are trying to break into AI PM, that is where the volume is. But the AI native roles are where the hardest product problems live.
Know which type you are applying for before you write a single line on your resume. The skills overlap. The interview questions do not.
Axis Two - Where in the AI Stack You Fit
After the role type, the second axis is where in the stack you sit.
The deeper you go, the harder the technical bar.
Layer 1 - Application PMs (60% of roles)
Own the end-to-end user experience. How users interact with AI. How to build trust. How to make AI reliable for everyday use.
This is the easiest entry point for someone converting from a traditional PM role. It builds on existing product management skills with AI knowledge layered on top.
Layer 2 - Platform PMs (30% of roles)
Build tools that other teams use.
Developer platforms
Model orchestration systems
Evaluation frameworks
Observability tools
You are not building for end users. You are building for other builders.
Layer 3 - Infra PMs (10% of roles)
Build the foundational systems that power everything above.
Vector databases
GPU orchestration
Model serving optimization
Kernel level compilation
The good news? The hardest roles are the smallest bucket.
The layer you choose determines the interview prep, the portfolio, and the companies you target. Pick your layer before you pick your first project.
2. The Core AI PM Fundamentals
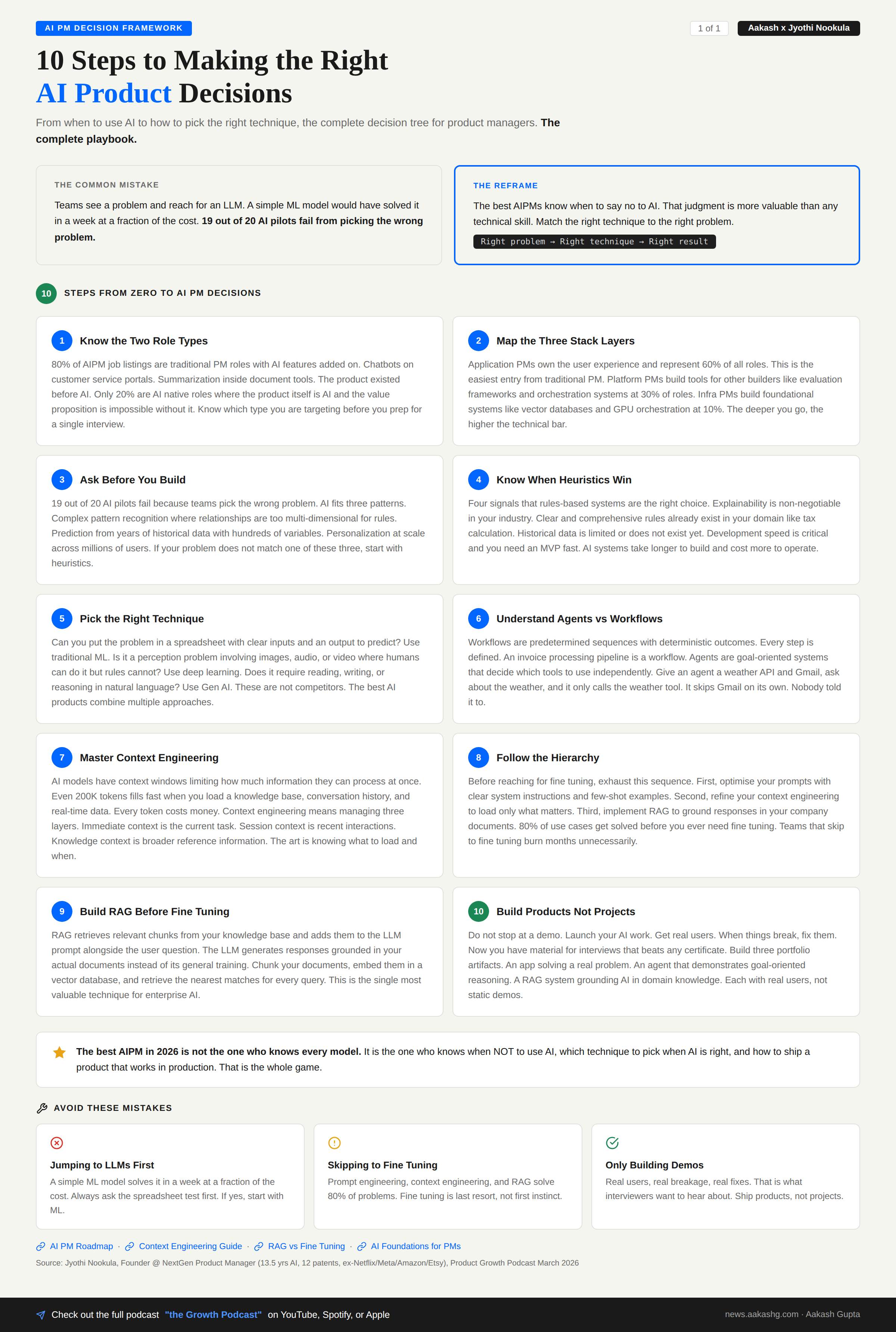
Three things separate the AI PMs who ship from the ones who flounder: knowing when to use AI, knowing which AI technique fits the problem, and understanding the technical building blocks well enough to make real product decisions.
Let’s go through each.
2a. When to use AI
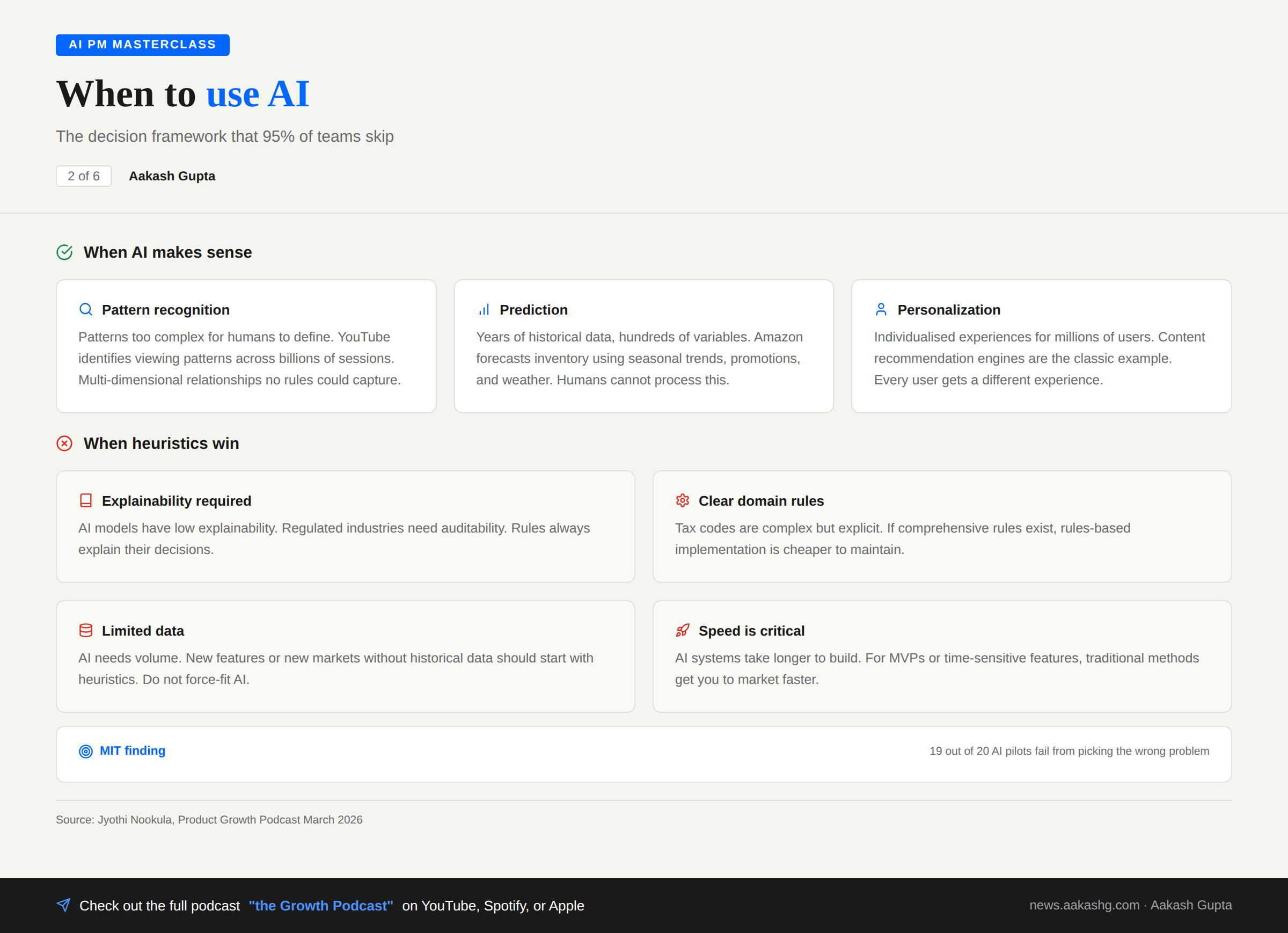
Here is where most teams get it wrong. Not a technical mistake. A product decision mistake.
MIT found that 19 out of 20 AI pilots fail. A key factor? Picking the wrong problems. Teams reach for AI when a rules-based system would have solved it faster, cheaper, and more reliably.
I covered the decision frameworks in my AI product strategy post. Here is the decision tree from the episode.
AI makes sense in three patterns
Pattern recognition in complex data. YouTube uses ML to identify patterns across billions of viewing sessions. The relationships are multi-dimensional. No rules could capture that.
Prediction from historical data. At Amazon, AI forecasts inventory needs based on hundreds of variables. Seasonal trends, promotions, weather patterns. Humans cannot process that many variables.
Personalization at scale. Individualised experiences for millions of users. Content recommendation engines are the classic example.
Heuristics win in four situations
Explainability is non-negotiable. AI models still have low explainability. Regulated industries need auditability.
Clear domain rules exist. Tax calculation. Tax codes are complex but explicit. Perfect for rules.
Data is limited. New features, new markets, no historical data. Do not force-fit AI.
Speed is critical. AI systems take longer to build. For MVPs, ship first. Add AI later.
The best AI PMs know when to say no to AI. That judgment is more valuable than knowing how to build a RAG system.
2b. Which AI to Use When
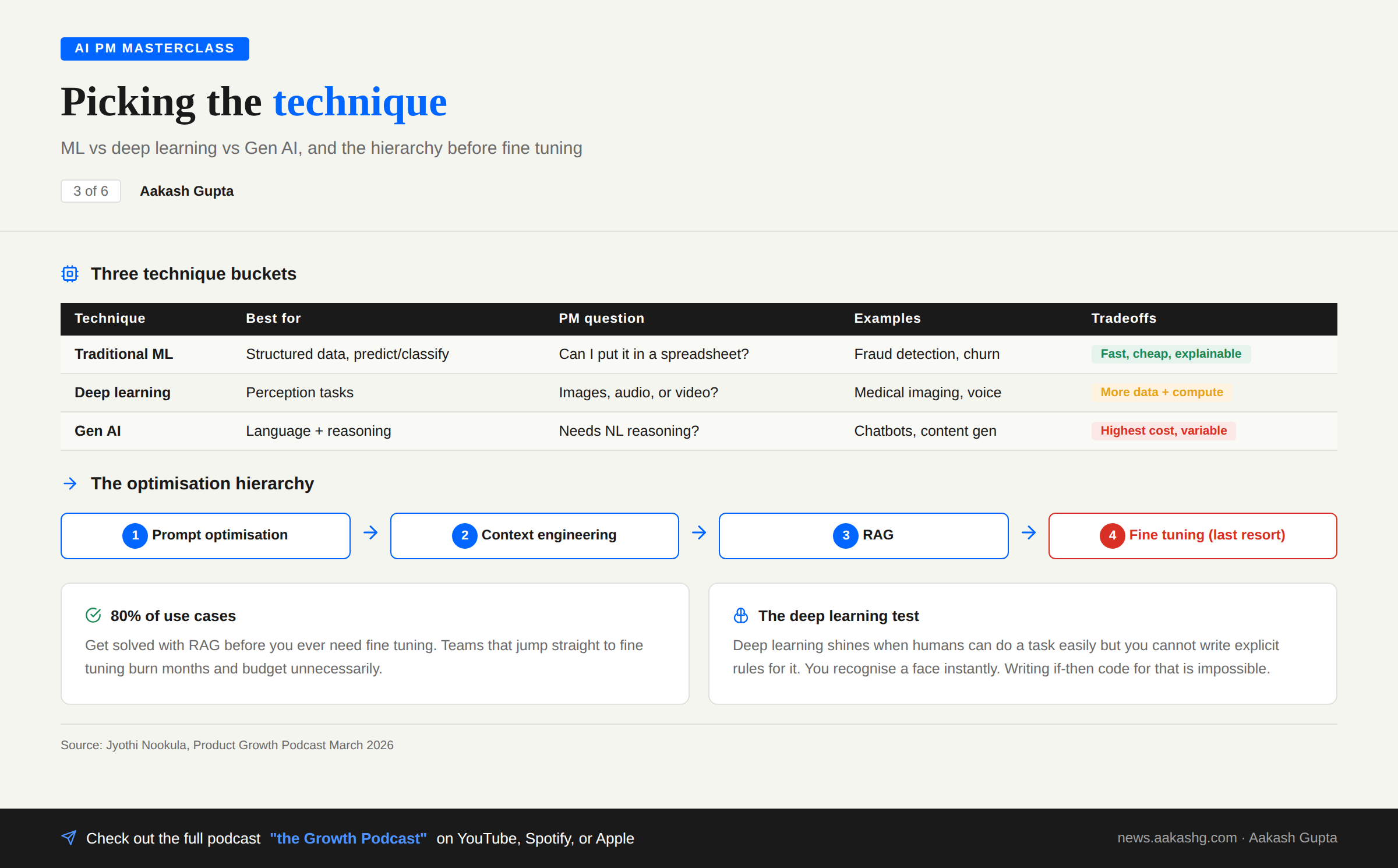
You decided AI is the right tool. Now which AI?
Most teams jump straight to LLMs when a simple ML model would have solved the problem in a week at a fraction of the cost. I wrote about this trap in my RAG vs fine tuning vs prompt engineering guide.
Traditional ML
Regression models. Random forests. XGBoost. Mature. Reliable. Still powers most of the AI you use daily.
Choose ML when:
You have structured data and need to predict or classify
You need the model to explain its decisions
Speed and cost matter
The PM question: Can I put this problem in a spreadsheet with clear input columns and an output I want to predict? If yes, start with ML.
Deep learning
Neural networks. Computer vision. Speech recognition.
Choose deep learning when:
You are dealing with images, video, or audio
Humans can do the task easily but you cannot write rules for it
Pattern recognition is too sophisticated for traditional ML
The face recognition example from the episode is perfect. You recognise a face instantly. Writing if-then statements to replicate that? Impossible.
Gen AI
LLMs. Diffusion models.
Choose Gen AI when:
Users need to interact conversationally
You are creating new text, images, or code
You need reasoning and synthesis across multiple sources
The optimization hierarchy (before fine tuning)
This is the most important takeaway for anyone building with AI right now.
Prompt optimization - better prompts, better results
Context engineering - what information gets loaded into the context window
RAG - dynamically retrieve relevant knowledge
Fine tuning - only if 1-3 do not work
80% of use cases get solved with RAG. Teams that jump to fine tuning because it is in the API documentation burn months unnecessarily.
These are not competitors. They are tools in your toolkit. The best AI products combine multiple approaches.
2c. The 3 Building Blocks of an AI Feature
These are three building blocks every AI PM must know. Each builds on the last.
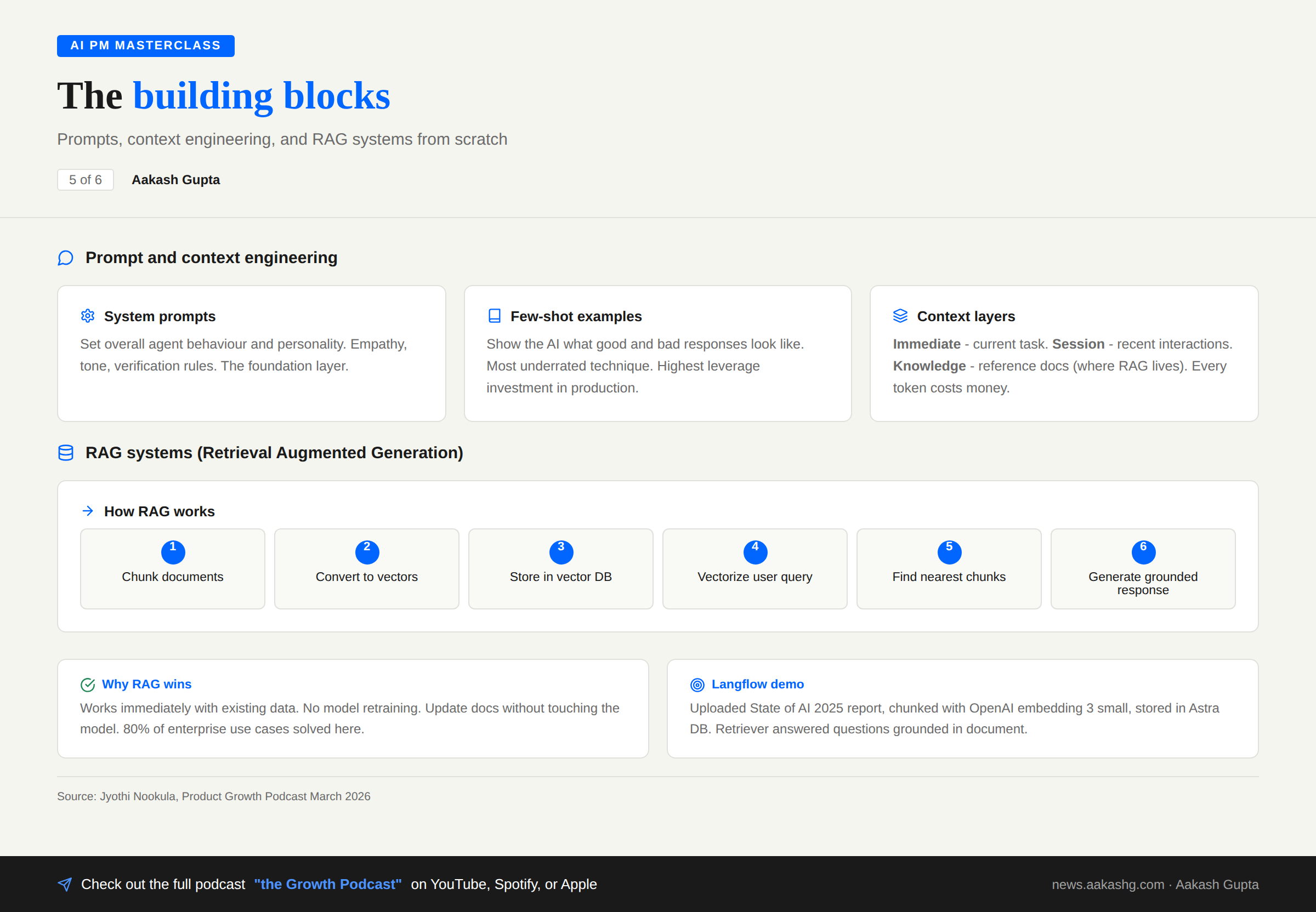
Building Block 1 - Agents vs workflows
An AI agent makes decisions and takes actions on its own. You do not tell it the exact order. It understands the goal and reasons its way there.
A workflow is the opposite. Predetermined sequences. Every step defined. Deterministic outcomes.
The agent architecture
Four components.
Perception - how it receives input (text, images, APIs)
Reasoning - where models live (LLMs, classifiers, planning algorithms)
Execution - how it takes action (text generation, API calls)
Learning - feedback mechanism for improving over time
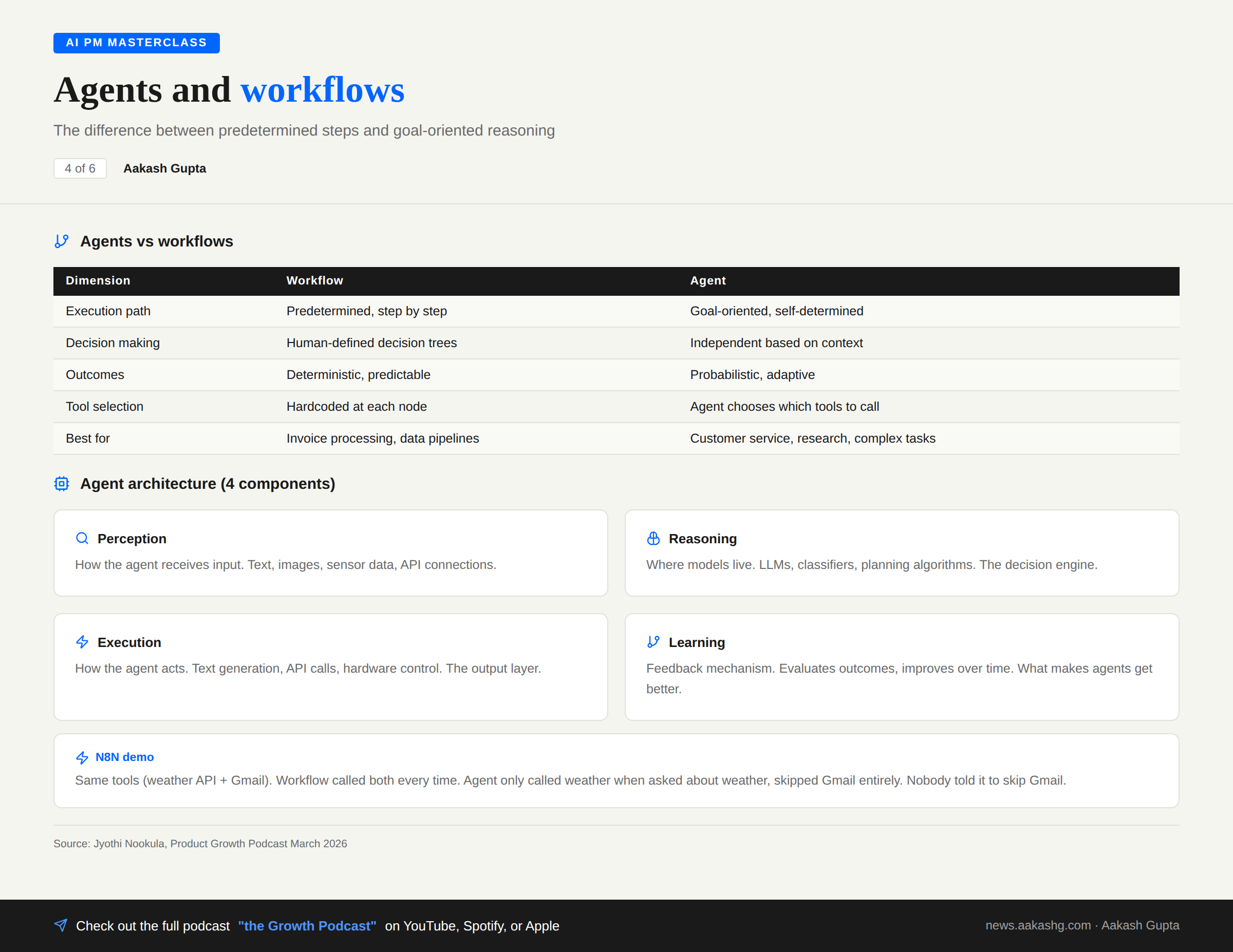
Building Block 2 - Prompts and Context Engineering
Prompts are the primary interface between you and the AI system. And most teams treat them as an afterthought.
Three layers to understand:
System prompts set overall behavior and personality. For a customer service agent, this means defining empathetic personality, professional tone, identity verification requirements, and escalation rules. The system prompt is the AI’s job description. Write a bad one and you’ll get a bad employee.
Few-shot examples are the most underrated technique in production AI. Show the model concrete examples of what a good response and a bad response look like. It sounds like extra work. In production, it is the single highest-leverage investment you can make. I’ve seen teams double response quality by adding 3-5 well-crafted examples instead of writing 3 more paragraphs of instructions.
Context engineering is where the real PM skill lives. I covered the full framework in my context engineering guide, co-written with an OpenAI product leader. The key insight: context engineering is a PM problem, not an engineering problem.
Three context layers matter:
Immediate context — the current conversation or task. What did the user just ask?
Session context — recent interactions and state. What happened earlier in this conversation?
Knowledge context — broader reference information. This is where RAG comes in.
Here’s why this matters commercially. Claude Sonnet has a 200K token context window. That sounds like a lot. It fills fast when you’re loading a knowledge base, conversation history, real-time data, and user prompts simultaneously. Every token costs money.
The teams that overspend on AI are almost always loading too much context into every interaction. A customer asks about their order status and the system loads the entire product catalog, the user’s full purchase history, and a 50-page return policy document. That’s wasteful. Context engineering is the art of knowing what to load and when — giving the model exactly enough information to answer well, and nothing more.
Building Block 3 - RAG (Retrieval-Augmented Generation)
RAG (Retrieval Augmented Generation) is the single most important technique for enterprise AI. I covered the fundamentals in my RAG vs fine tuning guide.
Take your company documents
Chunk them into smaller pieces
Convert chunks into vectors using an embedding model
Store vectors in a vector database
When a user asks a question, vectorize the query
Find the nearest matching chunks
Load those chunks alongside the user input into the LLM
The LLM generates a response grounded in your actual documents
The result: the LLM answers using your data, not its training data. It can cite sources. It stays current because you can update the document store without retraining anything.
Why RAG wins over fine tuning for most use cases
Works with your existing data immediately
No model retraining required
Update documents without touching the model
Cost is a fraction of fine tuning
80% of enterprise use cases are solved here
The failure mode to watch for: bad chunking strategy. If your chunks are too large, the model gets flooded with irrelevant context. Too small, and it loses the thread. Getting the chunk size and overlap right is where most RAG implementations succeed or fail.
RAG is not glamorous. But it solves most of the problems teams try to throw fine tuning at. Start here.
3. How to Become an AI PM
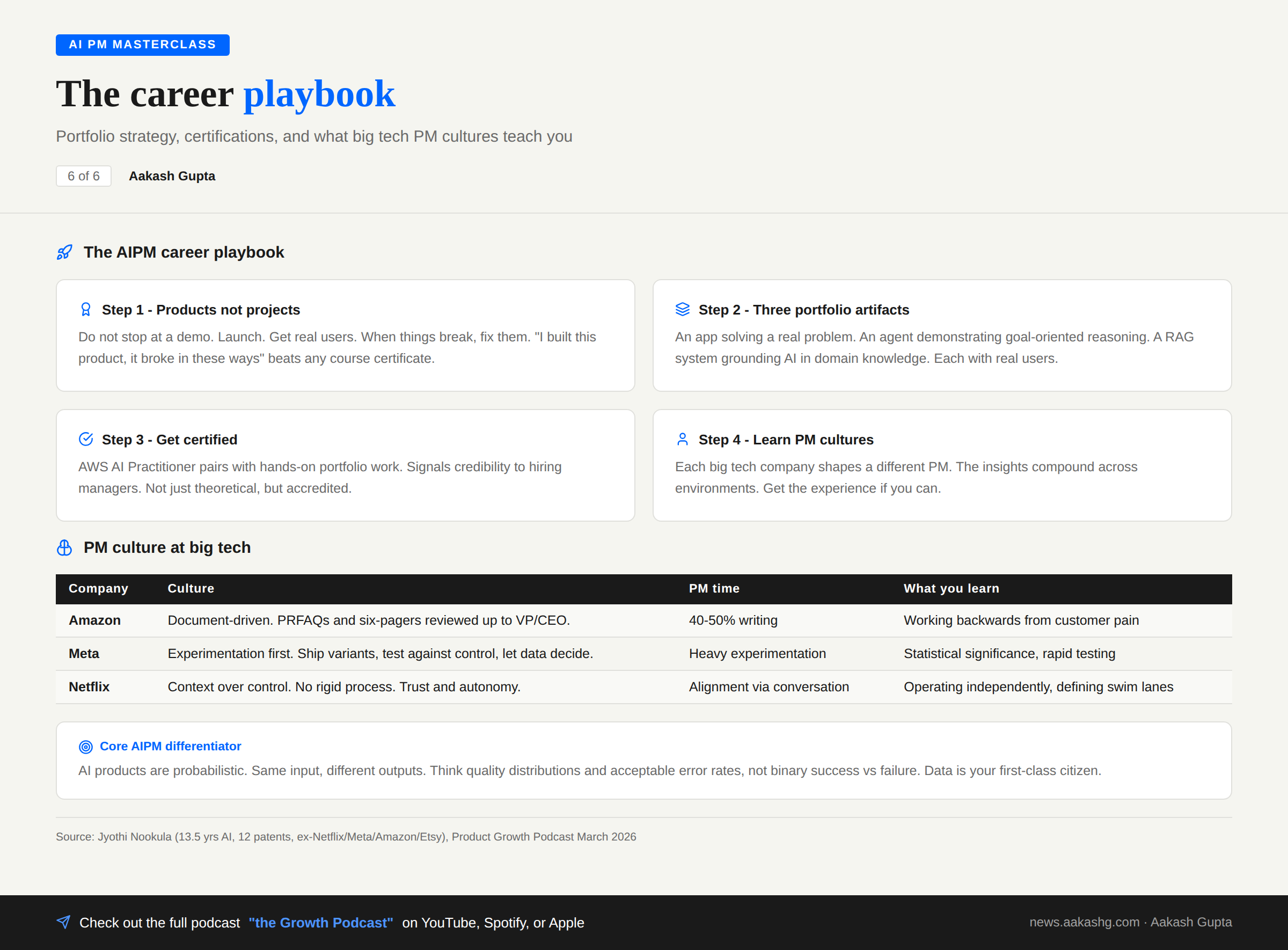
You know the role taxonomy. You understand the technical fundamentals. Now how do you get the job?
Four steps.
Step 1 - Build products, not projects
Do not stop at a demo. Launch. Get real users. When things break, fix them.
“I built this product. It broke in these ways. Here are the challenges I overcame.” That beats any course certificate in an interview.
The difference between a project and a product: a project is something you show in a portfolio. A product is something someone else uses. Hiring managers can tell the difference in 30 seconds.
Step 2 - Three portfolio artifacts
You need three things in your portfolio, each demonstrating a different AI PM competency:
An app solving a real problem you have. Not a tutorial clone. Not a toy. Something you actually use. This proves you can identify a problem and ship a solution.
An agent that demonstrates goal-oriented reasoning. Show that you understand the difference between workflows and agents. Build something where the AI makes real decisions about which tools to use and when.
A RAG system grounding AI in domain knowledge. Pick a domain you know well. Build a system that answers questions using your own documents. This proves you understand the most commercially relevant AI technique.
Each with real users. Not static demos.
Step 3 - Get certified
The AWS AI Practitioner certificate pairs well with hands-on portfolio work. It signals to hiring managers that your knowledge isn’t just theoretical. It covers the fundamentals - ML concepts, model selection, responsible AI - in a structured way that complements your portfolio.
Certifications alone don’t get you hired. Certifications plus shipped products do.
Step 4 - Learn the PM cultures
Each company shapes a different PM.
Amazon - document-driven. PRFAQs and six-pagers reviewed up to VP/CEO level. PMs spend 40-50% of their time writing. You become an exceptional writer.
Meta - experimentation first. Ship variants. Test against control groups. Let data decide. The most sophisticated experimentation infrastructure in the industry. You live and breathe statistical significance.
Netflix - context over control. No rigid process. No documentation requirements. Trust and autonomy. You define your own swim lane.
Amazon teaches thinking backwards from customer pain. Meta teaches rapid testing. Netflix teaches the power of autonomy.
The companies you work at shape who you are as a PM. The insights compound. Get the experience at even one of these environments if you can.
Where to find Jyothi Nookula
Related content
Podcasts:
Newsletters:
PS. Please subscribe on YouTube and follow on Apple & Spotify. It helps!