Check out the conversation on Apple, Spotify and YouTube.
Brought to you by:
Jira Product Discovery: Build the right thing
AI Product Strategy Certificate for Leaders: Get $550 off
Maven: Get $100 off my curation of their top courses
Today's Episode
"AI has been the biggest driver of change in experimentation I've seen in my career."
That's Frederic De Todaro, Chief Product Officer at Kameleoon (profitable SaaS with 2K+ customers).
Fred has been at Kameleoon for 12+ years. In that role, he's helped thousands of teams use AI to experiment faster and smarter.
In today’s episode he’s breaking down:
How AI changes experimentation
How to experiment with AI features
Last week, I covered how one aspect of this: vibe experimentation. Today’s video is the A to Z AI impact.
If you experiment at work, this episode is for you.
Your Newsletter Subscriber Bonus:
For subscribers, each episode I also write up a newsletter version of the podcast. Thank you for having me in your inbox.
(By the way, we’ve launched our podcast clips channel as well and we’re going to post most valuable podcast moments on this channel, so don’t miss out: subscribe here.)
What We're Covering
We’ve put together a complete guide to AI x Experimentation:
How to Experiment Well with AI
How AI transforms each step of the experimentation lifecycle
The two waves of AI that changed everything
Most common experimentation mistakes
How to Experiment with AI Features
AI experimentation keys
How to choose a north star
How to measure RAG systems
1. How to Experiment Well with AI
1a. How AI Changes Each Step of the Experimentation Lifecycle

Fred broke down experimentation into four core steps and showed exactly how AI transforms each one. But here's what's really happening: AI isn't just changing experimentation it's changing how we build products entirely.
Think about it. Most product ideas never get tested because the build phase takes too long. You write a PRD, wait for design, then wait 2-3 sprints for development. By then, you've moved on to other priorities.
This creates a massive gap between what we think users want and what they actually want.
AI bridges that gap by removing the biggest bottleneck: turning ideas into testable experiences.
The Traditional Experimentation Loop looks like this:
Ideate: Come up with a hypothesis
Build: Create the variation (the bottleneck!)
Configure: Set up targeting, metrics, sample size
Analyze: Look at results and decide
How AI Helps Each Step

Ideation (3/5 Difficulty → AI-Assisted)
AI can now generate experiment ideas with full context about your business, users, and website. But here's the key: you still need to provide the business context that AI doesn't have.
As Fred put it: "The PM comes with all the internal constraints that the AI does not have. Why are we working on that idea? What is the assumption? What will success look like?"
Building (5/5 Difficulty → Almost Fully Automated)
This is where the magic happens. The build phase has always been the bottleneck. Most teams can't experiment because developers are busy building roadmap features.
AI changes this completely. You can now go from idea to live experiment without touching code.
Configure (4/5 Difficulty → AI-Powered with Human Review)
AI can determine targeting, set up metrics, and even choose the right statistical method. But you need humans in the loop - the PM for business context and a data scientist to validate the approach.
Analyze (3/5 Difficulty → AI-Enhanced)
AI can identify patterns at scale that humans would miss. It can spot when an experiment isn't working overall but performs well for specific segments (like mobile users).
The key: AI makes experimentation faster and more accessible, but humans are still critical for context, strategy, and validation.
1b. The Two Waves of AI in Experimentation
Fred explained how AI has evolved in two distinct waves:
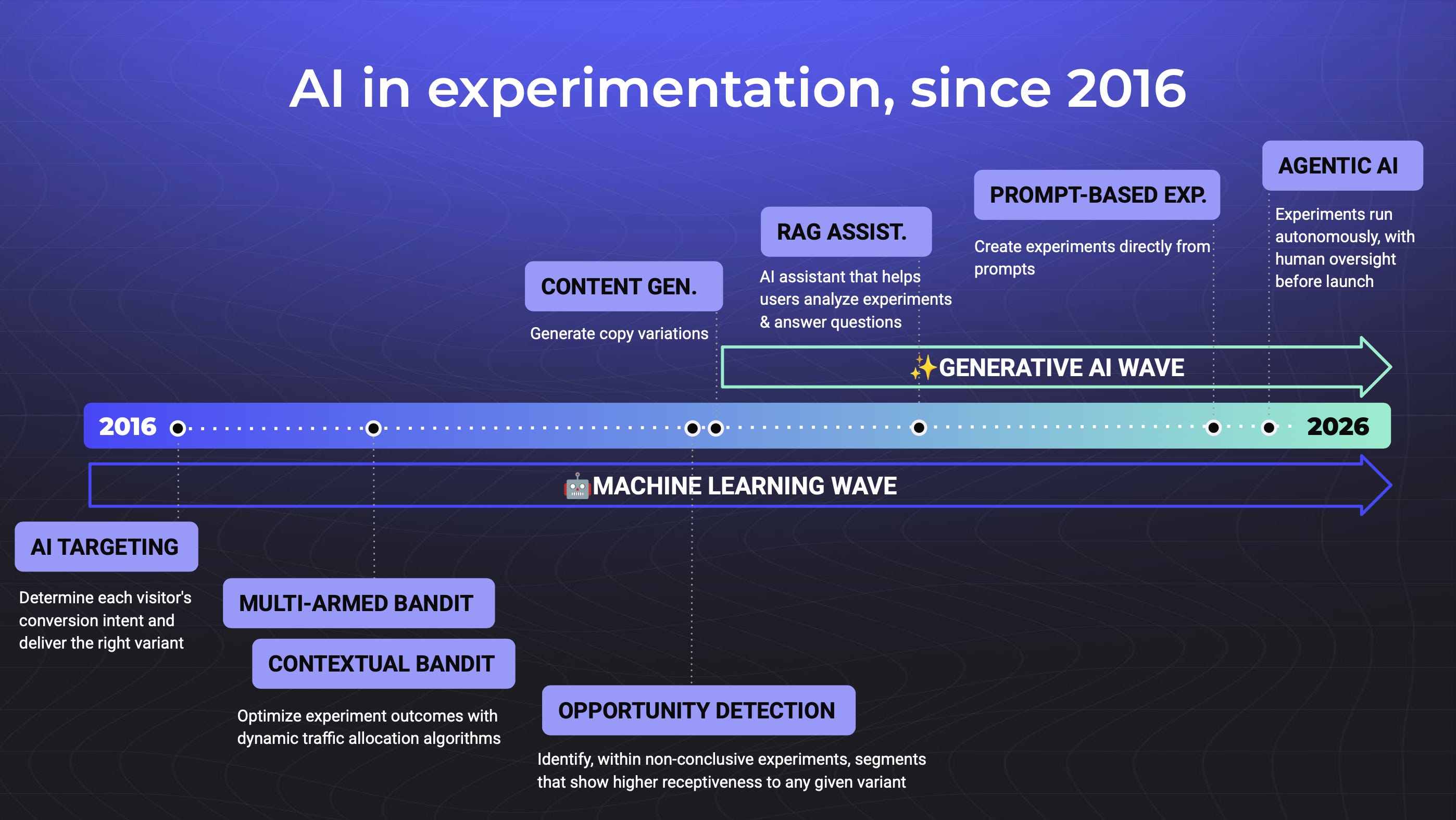
Wave 1: Machine Learning
This wave focused on optimization and intelligence within existing processes:
AI Targeting revolutionized how we personalize experiences. Instead of showing the same popup to everyone, AI scores users based on behavior patterns. Think of it like a digital sales rep it reads the signals and shows discounts only to users who need them to convert.
Multi-Arm Bandits solved the time-sensitive content problem. Perfect for media companies that need to know within hours which headline drives more clicks. You trade some statistical accuracy for speed, but when time matters more than perfect measurement, this wins.
Contextual Bandits took personalization to the next level. Instead of finding the best variation for everyone, it finds the best variation for each individual user. Requires significant traffic, but the results are powerful true hyper-personalization at scale.
Opportunity Detection turned failed experiments into learning goldmines. When an experiment doesn't work overall, AI automatically drills down to find segments where it does work. "This feature failed overall, but it increased conversions 25% for mobile users" insights that would take hours of manual analysis.
Wave 2: Generative AI
Then everything changed. Generative AI didn't just optimize existing processes it reimagined what was possible:
Content Generation started simple but proved immediately valuable. AI creates multiple copy variations automatically. Fred's team sees this used heavily for popups and banners where teams can test different messaging approaches without writing dozens of variations manually.
RAG Assistants became like having an experimentation expert on call 24/7. These AI chatbots answer complex questions like "What statistical method should I use for this experiment?" and generate code for feature flags and SDKs. They have access to your entire experimentation knowledge base.
Prompt-Based Experimentation is the breakthrough that changes everything. This is what Fred demonstrated live turning any idea into a running experiment with just a text prompt, working directly on your live website. No prototyping phase, no development time, no waiting.
The future is Agentic AI that handles experimentation for you. But we’re not there yet.
1c. The Biggest Mistakes PMs Make with Experimentation
Fred called out three common misconceptions:

→ Experimentation Will Slow Us Down
The Reality: Harvard Business Review found a direct correlation between experiments run annually and revenue growth. More experiments = faster growth.
Why This Happens: Teams think they need perfect features before shipping. But Fred's advice: "Ship early and iterate until you reach your goal. You'll learn so much more in a short period of time."
→ We Don't Have Enough Traffic
The Reality: Teams validate features with 10 user interviews but think they need massive traffic for experiments.
The Truth: Sample size depends on conversions, not just visitors. The more commercial your metric, the faster you'll get insights.
→ Product Discovery Is Enough
The Reality: Discovery and experimentation serve different purposes.
Discovery tells you what users say they want. Experimentation tells you what they actually do.
Both are essential for the full picture.
2. How to Experiment with AI Features
2a. How to Measure AI Features
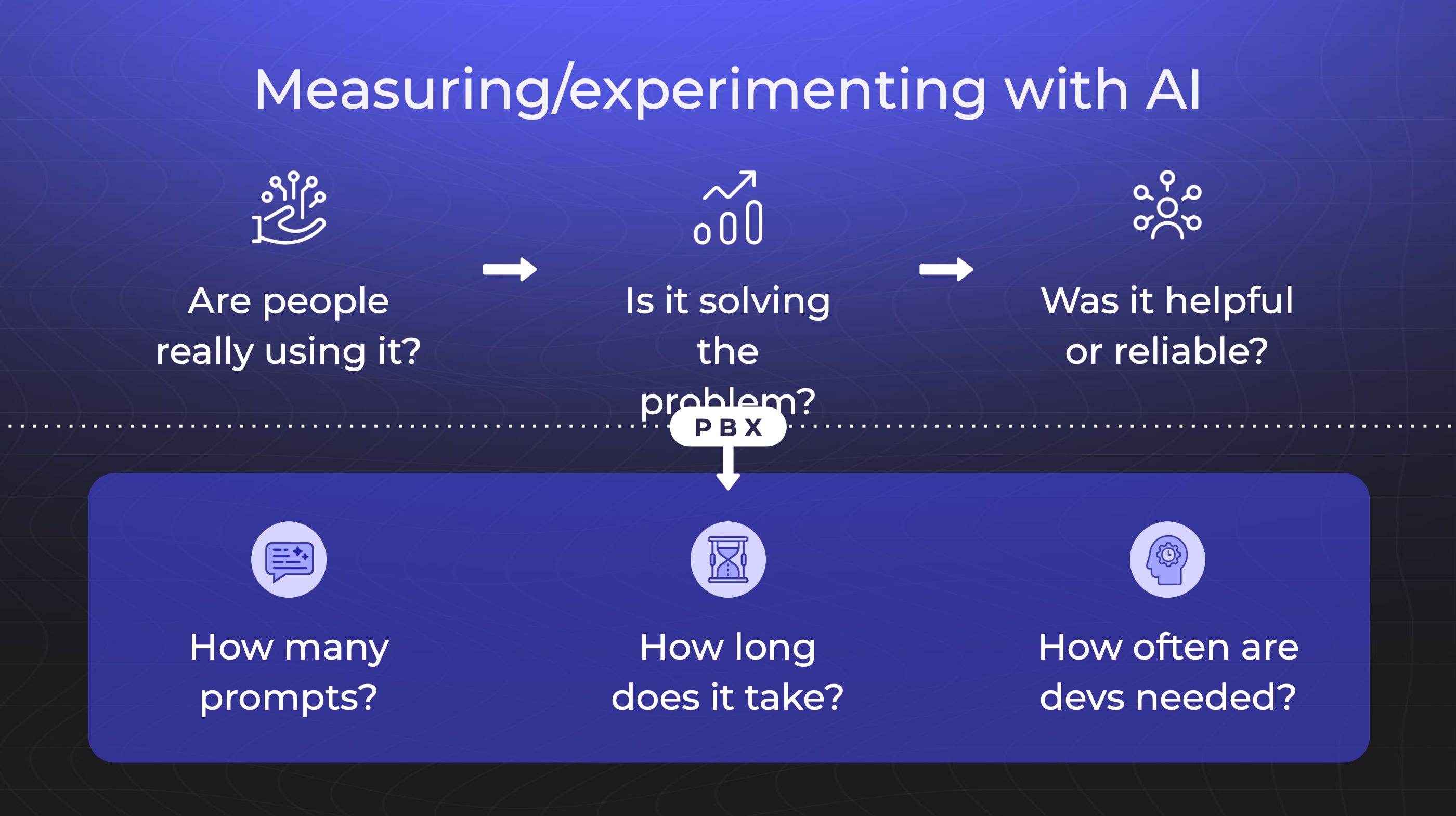
Most teams get this wrong. They launch AI features, see some usage, and call it a win. But Fred shared the framework Kameleoon uses to measure their AI features properly.
It's not just about usage. It's about value creation.
Three business metrics matter:
Usage/Adoption: Are people using the feature? (This is table stakes)
Outcome: Does it solve the problem users came for? (This is where most teams stop)
Experience: Do users find it helpful and reliable? (This is what separates good from great)
Here's what makes this framework brilliant: every metric connects to real business value:
Speed Metric: How many prompts does it take to create an experiment? If users need 10+ prompts, something's broken with the AI. The goal is minimal friction from idea to experiment.
Time Metric: How long from first prompt to experiment live? Traditional approach: days or weeks. Their target: minutes. This metric shows whether AI actually solves the speed problem.
Developer Dependency: How often do developers still need to step in? Traditional experimentation: 80%+ of experiments need custom code. Their target: reduce to 20%. This measures whether AI truly democratizes experimentation.
2b. How to Choose a North Star
Kameleoon tracks one simple metric: the number of experiments running daily on their platform.
Why this works:
Simple to measure and understand across the organization
Actionable by every team (product, customer success, marketing can all influence it)
Highly correlated with revenue growth
Shows the real value of democratizing experimentation
When this number goes up, it means either new customers or existing customers running more experiments. Both are wins.
AI experiments must move the business north-star.
2c. Measuring RAG Systems (The Technical Side)
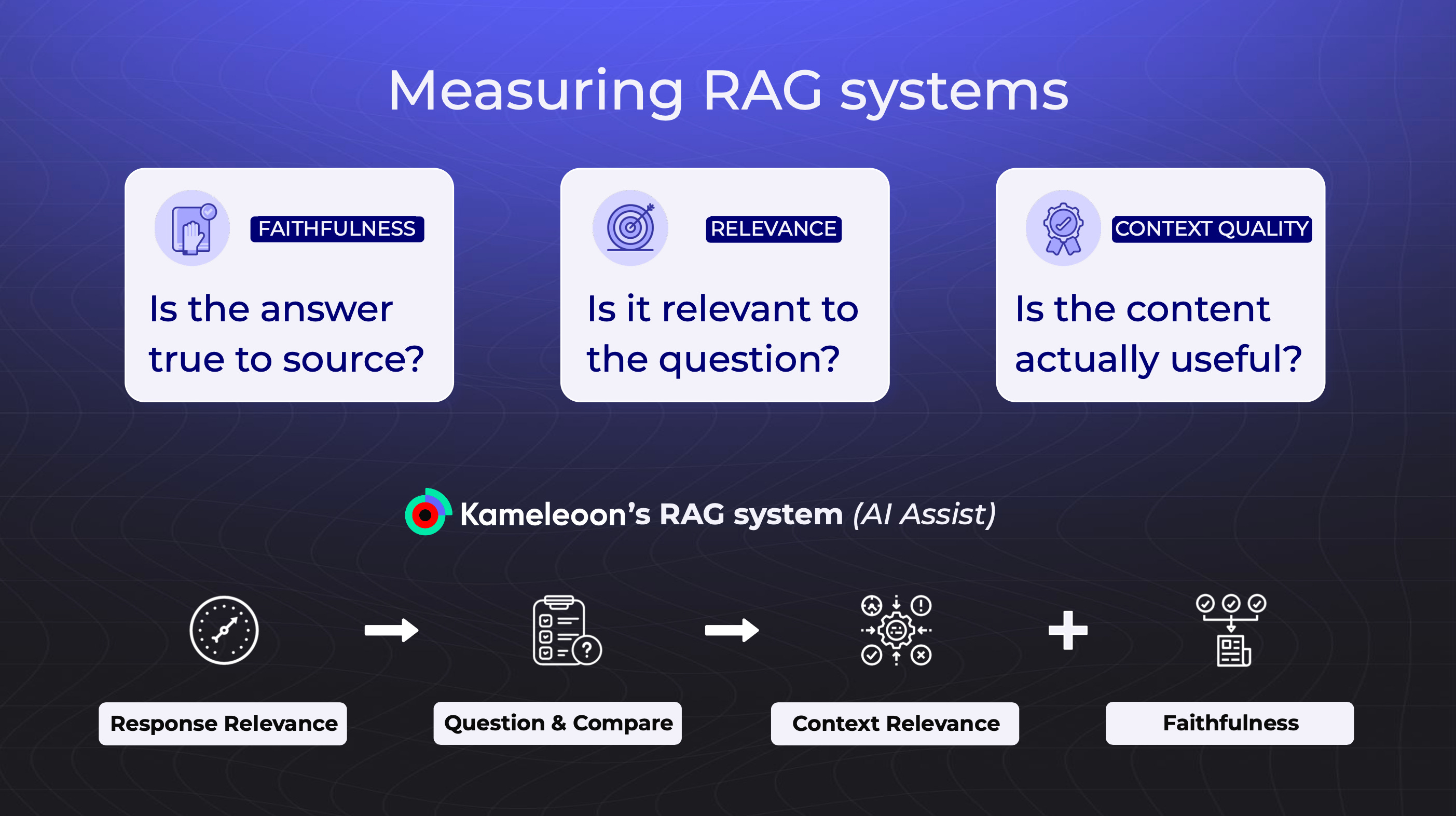
For AI assistants and chatbots, Fred recommends three technical metrics:
Accuracy: Is the answer based on real, current documentation? Relevance: Does it actually answer the user's question? Context Quality: Did it use helpful, up-to-date sources?
The LLM Judge Technique: Use one AI to evaluate another. Have an LLM generate questions based on the chatbot's answer, then check if those questions are similar to what the user actually asked. It's automated evaluation at scale.
Key Takeaways

Where to find Frederic
Related Content
Podcasts:
Newsletters:
P.S. More than 85% of you aren't subscribed yet. If you can subscribe on YouTube, follow on Apple & Spotify, my commitment to you is that we'll continue making this content better.