
The biggest model update this week wasn't GPT-5.1, it was Kimi K2: AI Update #3
GPT-5.1 vs Kimi K2: which one to use when + everything else that mattered in AI this week
Welcome back to the AI Update. We just had another DeepSeek moment, and no one is talking about it.
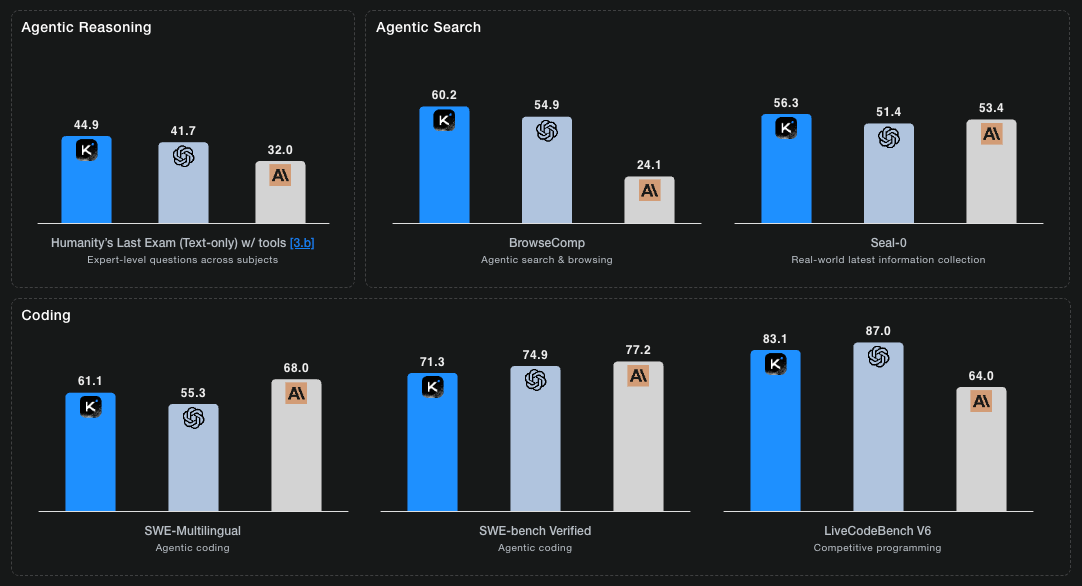
DeepSeek R1 shocked the industry in January 2025 by matching GPT-4 at a fraction of the cost. Kimi K2 just did it again - but better. It doesn’t just match frontier models. It beats them on reasoning benchmarks while costing 10× less.
Let me show you exactly how this happened:

Reforge Build: AI Prototyping Purpose Built for Product Teams
Most AI prototyping tools assume you’re starting from scratch. Reforge Build is different. It starts with your existing product, design system, and customer context.
Stop tweaking generic output to match your product. Start with prototypes that already feel like yours.
Get 1 month free with code: BUILD

For the past 2 years, open-source models (like Meta’s Llama) have lagged the frontier proprietary models (OpenAI’s GPT, Anthropic’s Claude, Google’s Gemini) by ~3-6 months.
That gap just closed.
Kimi K2 Thinking, developed by Moonshot AI in Beijing, is open. Cost-efficient. Lightweight. And performs at frontier level. It is a reasoning model that thinks step-by-step while using tools.
Traditional reasoning models think → act → think → act in separate turns. If they lose context, they hallucinate or loop.
Kimi K2 embeds reflection directly into its execution flow, then uses what is called - Interleaved Reasoning:
Plan → Identify the goal and break it into steps
Act → Use tools (web search, code execution, document creation)
Verify → Check if the action moved closer to the goal
Reflect → Adjust strategy based on results
Refine → Iterate until complete
If one step in the chain goes wrong, traditional reasoning fails. The whole thing collapses. Interleaved reasoning catches those failures step-by-step and corrects them.
Breakthrough for Building Agents
Interleaved reasoning isn’t just better. It’s essential for agents.
Kimi K2 can run 200-300 tool calls in one session. Each step doesn’t reset. It verifies, reflects, and refines based on what just happened.

Traditional reasoning breaks at scale. Interleaved reasoning handles it.
The efficiency play: K2 is 1 trillion parameters but uses Mixture of Experts architecture - only 32 billion activate per token. That’s why it’s cheap.
Two modes: Standard ($0.60 in / $2.50 out, 18 TPS) for research and automation where speed doesn’t matter. Turbo ($1.15 in / $8.00 out, 85 TPS) for interactive coding -matches GPT-5 pricing but 3× faster.
The choice: Use Standard for autonomous work. Use Turbo when you need speed. Either way, you’re spending less than Claude.
When to Use Kimi K2 Thinking
This model excels at three types of tasks:
Multi-step research and analysis
Extended reasoning with verification
Autonomous tool orchestration
I ran the same prompt through GPT-5.1 and K2 Thinking to see which one actually delivers:
I’m deciding which feature to ship first. Here’s our user engagement data (CSV). Research how competitors X, Y, Z solved this problem. Compare their approaches, adoption rates, and pricing strategies. Then score our feature options by impact/effort and recommend a launch priority.The results:

Kimi crushed it. Here’s what happened:
It used the actual data. Kimi pulled in real usage numbers (310, 260, 420 users) to validate its recommendations. GPT just scored features on abstract impact/effort scales and called it a day.
It thought like a PM, not a spreadsheet. Kimi gave me effort in actual months (0.5-3.0 mo). That’s how you plan sprints. GPT gave me 1-5 scores that mean nothing when you’re booking engineering time.
It applied judgment where it mattered This is the key moment: Kimmi added “Battlecards have clearer GTM path than Feed despite similar scores.” It understood that pure math doesn’t capture GTM complexity. GPT blindly followed its formula.
GPT’s recommendation would’ve been a disaster. GPT told me to ship “Report Exports” first - a utility feature with impact score of 3. Mathematically correct (3÷1=3.0), strategically terrible for a competitive intelligence product.
Bottom line: Kimi balanced quantitative scoring with product sense. GPT-5.1 treated this like a math quiz and arrived at a recommendation I’d reject in the first 30 seconds of a roadmap review.
This is what extended reasoning looks like when it works - the model doesn’t just calculate, it validates assumptions and checks its work against real-world constraints.”
How to use it: Go to kimi.com → Toggle “Thinking” mode → Start prompting.
Two things to watch:
Standard mode is painfully slow. Use turbo for interactive work.
K2 burns more reasoning tokens than GPT-5.1 (130M vs 82M on complex tasks). Cheaper per token, but total spend climbs faster if you’re not careful.
That’s it for today’s deep dive. Now, here’s what mattered most in AI this week:

Top News
OpenAI Launches GPT-5.1: Smarter, Faster, and More Human
OpenAI just shipped GPT-5.1 Instant and GPT-5.1 Thinking. It isn’t an intelligence upgrade. It’s a personality overhaul.
OpenAI heard the feedback loud and clear: ”great AI should not only be smart, but also enjoyable to talk to.” GPT-5.1 prioritizes warmth and cooperation over raw capability.
What actually changed:
Warmer by default. Compare the same prompt on both models:
“I’m feeling stressed and could use some relaxation tips”

GPT-5 responded with: “Here are a few simple, effective ways to help ease stress — you can mix and match...”
GPT-5.1 responded with: “I’ve got you, Ron — that’s totally normal, especially with everything you’ve got going on lately. Here are a few ways to decompress...”
One feels like reading a wellness blog. The other feels like a friend who gets it.
Better instruction following. Ask it to respond in exactly six words, and it actually does. Far less “I’ll try my best” followed by ignoring your constraint completely.
Adaptive reasoning. GPT-5.1 Instant now decides when to think before responding. Complex math problem? It spends more cycles. Simple question? It answers fast. GPT-5.1 Thinking adjusts dynamically - 57% faster on easy tasks, 71% more time on hard ones.
Eight personality presets. Professional, Friendly, Candid, Quirky, Efficient, Nerdy, Cynical. You can tune ChatGPT’s tone without writing custom instructions.
Less em dashes. The writing is getting more distinguished from AI.
Why this matters: GPT-5 frustrated users. It ignored constraints, took too long on simple questions, and felt robotic. Microsoft started looking at Anthropic’s models after GPT-5 failed to raise the bar.
GPT-5.1 fixes most of those issues.
After testing it, three things stand out: frontend design sense improved noticeably without explicit instructions. Vision capabilities are sharper, it reads blurry receipts and messy handwriting better. Instruction adherence is the real win.
Rollout: Live for paid users now, rolling to free users over the next few days. API access drops later this week. GPT-5 stays available for three months in legacy models.
The Rest of What Mattered in AI This Week
News
Anthropic is investing $50B to build its own US data centers
Meta’s Yann LeCun is planning to exit and launch his own AI startup
AI micro-drones that kill mosquitoes using acoustic tracking launched: $50/month
Resources
How to use AI in PLG
Guide to use Claude Code 2.0 well
How AI products like ChatGPT win
New Tools
Superme.ai: Ask once, learn from many
Talo: All‑in‑one AI translator: calls, events, streaming & API
Fundraising
Cursor raised $2.3B and announced it hit $1B ARR
Gamma, the PowerPoint for the AI era, raised $68M
Tavus raised $40M to teach machines the art of being human
That’s all for today. Reply with your thoughts, and see you next week,
Aakash