
PM's Guide to Karpathy's Autoresearch
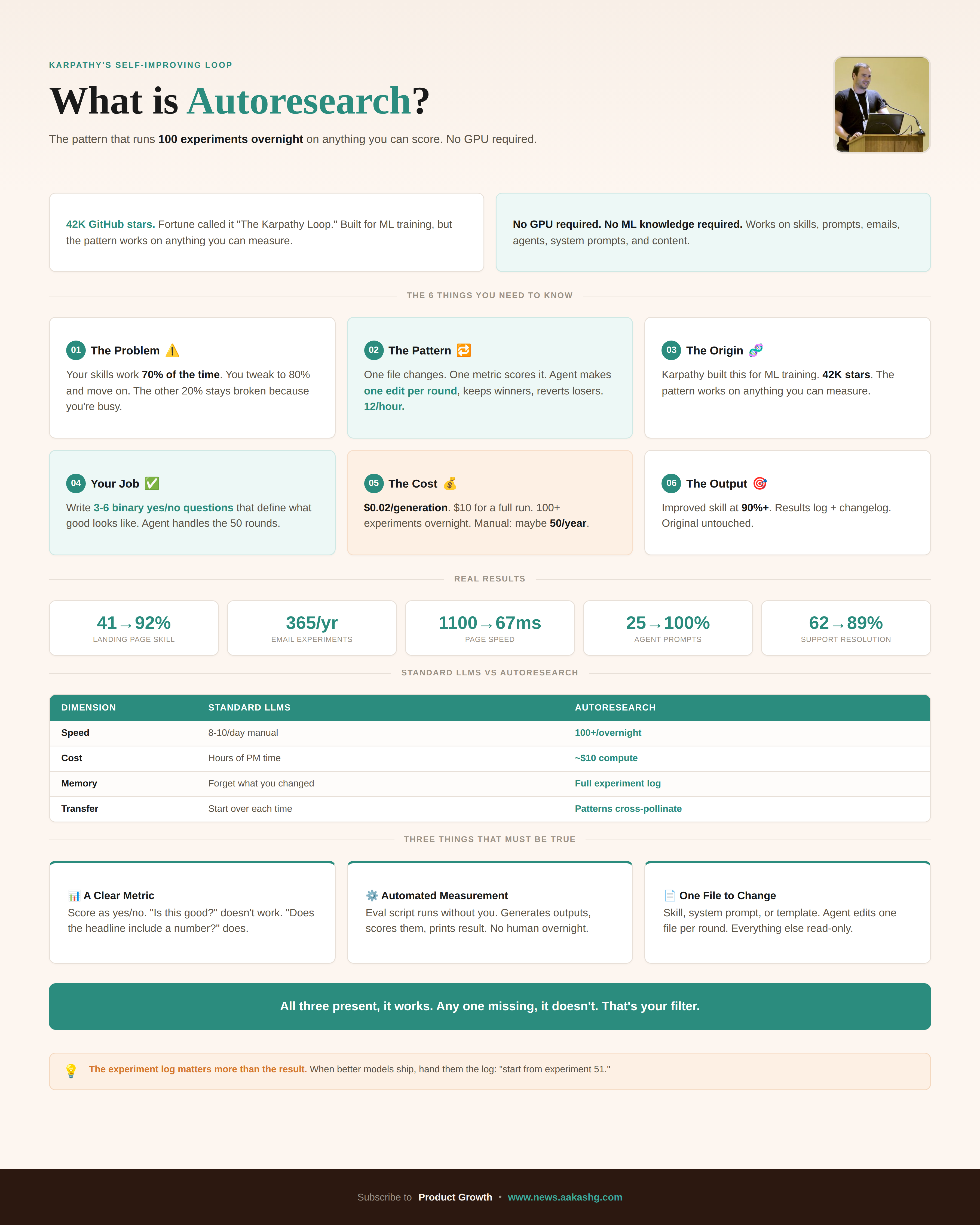
The 42K-star repo everyone thinks is for ML researchers. It works on anything you can score
You built a skill, a prompt, a system prompt. It works 70% of the time. You tweak it, get to 80%, and move on because you’re busy.
Andrej Karpathy built a system that runs the other 500 rounds for you while you sleep. He called it autoresearch.
42,000 GitHub stars. Fortune called it “The Karpathy Loop.” Shopify CEO Tobi Lutke pointed it at Shopify’s templating engine and got 53% faster rendering from 93 automated commits.
Everyone covered the ML side. Most PMs closed the tab thinking it wasn’t for them. That’s a mistake. The pattern underneath has nothing to do with GPUs or neural networks. It works on anything you can score.

I’ve spent two weeks pulling apart Karpathy’s repo, the community forks, and the real-world applications people are building on top of it.
Today’s Post
I’ve built the PM’s Ultimate Guide to Autoresearch, covering:
What autoresearch actually does
Why this matters if you’re a PM
How to set it up
Six high-value use cases
Why the experiment log matters
Where Karpathy is taking this next
The complete toolkit: skill, eval templates, and analyzer
Quick setup if you want to follow along: install Claude Code, clone the autoresearch repo with git clone https://github.com/karpathy/autoresearch, and pick the skill or prompt that frustrates you most. That’s your starting point.
1. What autoresearch actually does


Let me ground you in the original before I show you the PM version.
Karpathy trains small language models as side projects. Like every ML researcher, he was stuck in the same grind: tweak the training script, run an experiment, wait for results, check if the model got better, decide whether to keep the change or throw it away, then start the whole cycle again. A productive day might get through 8-10 of these rounds, and most of that time is spent waiting for the GPU.
So he built a system that does the entire cycle autonomously.
The repo has three files. train.py is the training script and the only file the agent is allowed to modify. prepare.py is the evaluation harness that scores the model, and the agent cannot touch it (if it could, it would just make the test easier instead of making the model better). And program.md is the instruction file that tells the agent how to behave, what to try, when to keep changes, and when to revert.
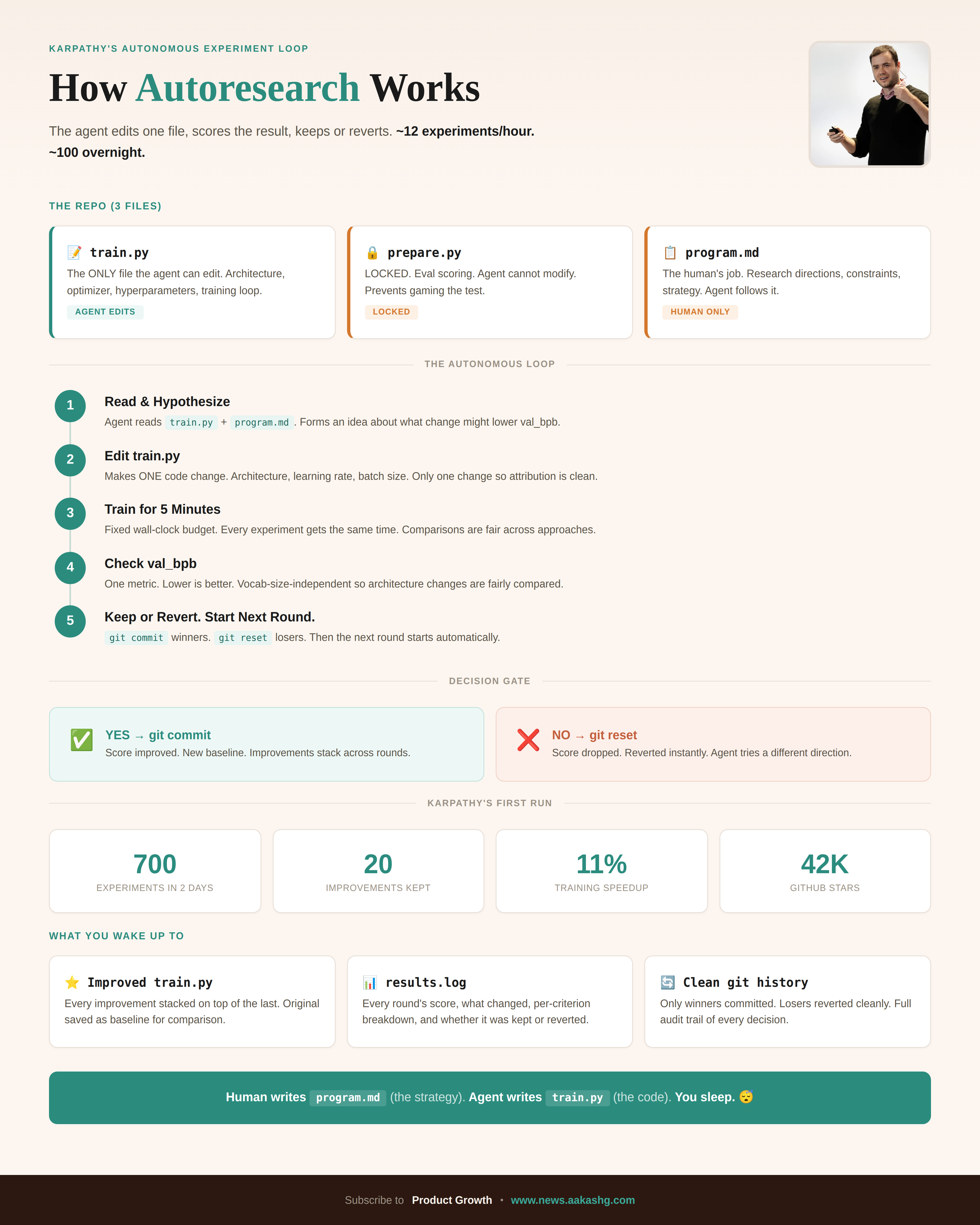
The loop works like this. The agent reads the code, forms a hypothesis about what might improve the model, makes a change to train.py, runs a 5-minute training experiment, and checks the metric (validation bits per byte, a single number where lower means better). If the score improved, the change gets committed to git and becomes the new baseline. If it didn’t improve, git reset wipes the change instantly. Then the agent starts the next round.
That gives you about 12 experiments per hour, roughly 100 overnight.
Karpathy left it running for two days. The agent found 20 improvements on code he’d already hand-tuned for months, including a bug in his attention implementation he’d missed entirely. All 20 stacked and transferred to a larger model, producing an 11% speedup.
Shopify CEO Tobi Lutke tried it the same night. He ran 37 experiments overnight and woke up to a 0.8B parameter model outperforming his hand-tuned 1.6B model. Half the parameters, better results.
Then he pointed the pattern at Liquid, Shopify’s templating engine, and got 53% faster rendering and 61% fewer memory allocations from 93 automated commits.

This is a new way to optimize anything.
2. Why this matters if you’re a PM
My run on a landing page skill: 41% to 92% in 4 rounds. Three changes kept, one auto-reverted.
The pattern works because it removes the bottleneck every PM actually faces: you know the prompt could be better, but you'll never run 50 iterations manually.
It only works when three things are true:
A clear metric. Score the output as a number, not a feeling. “Is this good?” doesn’t work. “Does the headline include a specific number?” does. Yes or no. Add up the yeses across 30 test runs and you have a score the agent can optimize against.
A measurement tool that runs without you. Claude Code builds an evaluation script that generates outputs, scores them against your criteria, and prints the result. No human in the loop. The scoring runs programmatically so the loop runs overnight.
One file the agent can change. Your skill markdown, your system prompt, your email template. The agent edits this one file per round. Everything else is read-only.
All three present, it works. Any one missing, it doesn’t. That’s your filter.
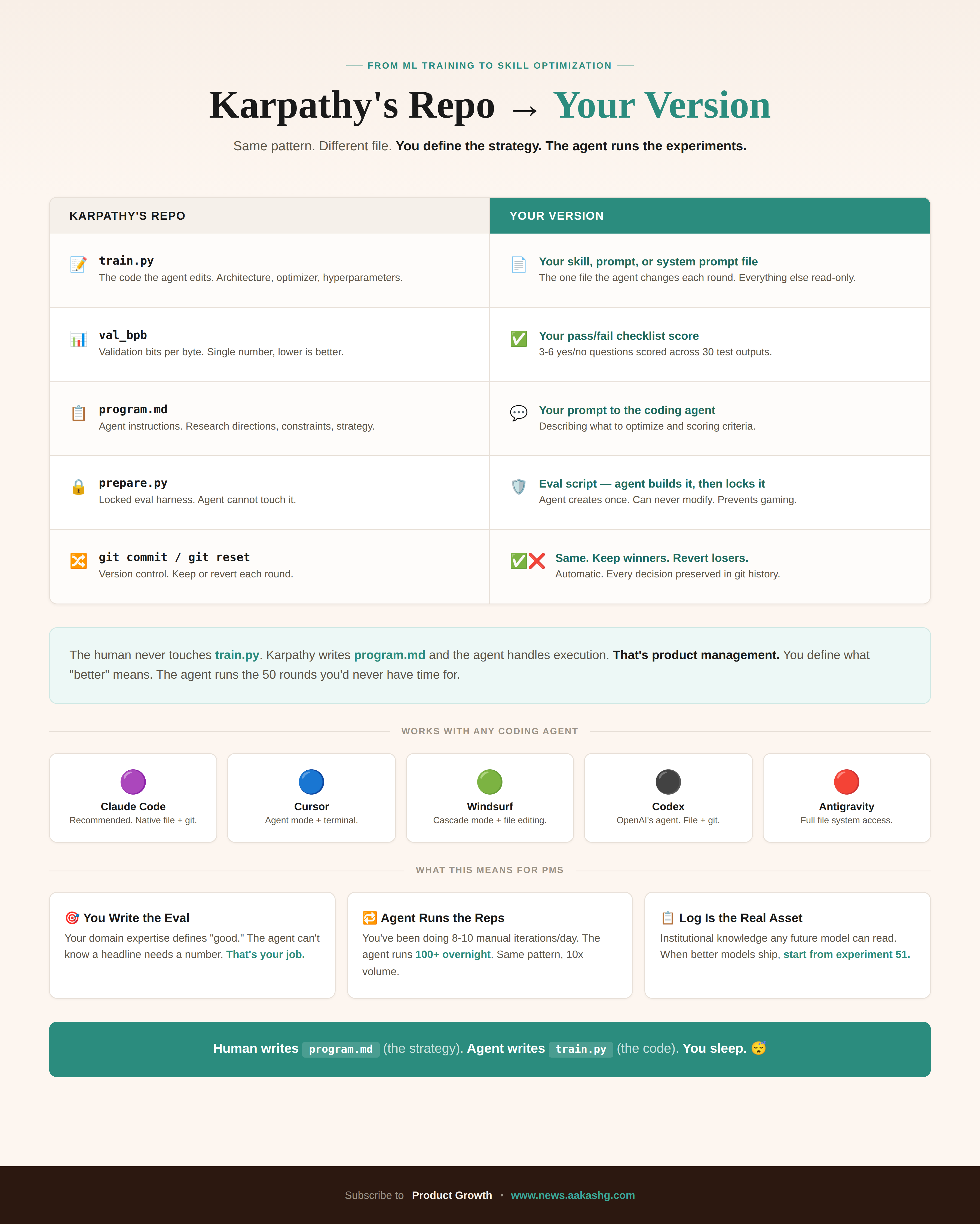
The human never touches train.py. Karpathy writes program.md and the agent handles execution. That’s product management. You define what “better” means. The agent runs the 50 rounds you’d never have time for.
I use Claude Code for this. But it works on any coding agent that can read files, edit files, and use git. Cursor, Windsurf, Codex, Antigravity.
🔒 Below: the 3-step setup, 6 use cases with copy-paste prompts and eval criteria for each, the experiment log walkthrough that Karpathy says matters more than the result itself, and a downloadable toolkit with a skill improver, 10 eval templates, and a results analyzer.
Keep reading with a 7-day free trial
Subscribe to Product Growth to keep reading this post and get 7 days of free access to the full post archives.