


AI Evals: Everything You Need to Know to Start
When it comes to important skills for building in AI (especially for PMs and engineers), evals are at the top of the list. So, today, we break down evals in-depth with an expert
Just like you can't be a PM without using analytics, you can't be a PM on AI products without evals.
Unlike traditional software, LLM pipelines do not produce deterministic outputs.
A response may be factually accurate but inappropriate (i.e., the “vibes are off”).
They may sound persuasive while conveying incorrect information.
The core challenge is: How do we assess whether an LLM pipeline is performing adequately? And how do we diagnose where it is failing?
To give you the absolute expert POV on this, I’ve teamed up with Hamel Husain, one of the most recognized names in AI Evals industry-wide.
I have been taking his AI Evals for Engineers & PMs course, and it’s great. Use my code ag-product-growth to get over $800 off.
Defining Evals
What is an LLM evaluation (eval)?
It’s the systematic measurement of LLM pipeline quality. A good evaluation produces results that can be easily and unambiguously interpreted. It goes beyond a single number.
Evals can be operationalized in many different ways.
Three common ways are:
Background Monitoring - passively, without interrupting the core workflow, these evals detect drift or degradation.
Guardrails - in the critical path of the pipeline, these evals run can block the output, force a retry, or result in the fall back to a safer alternative.
To Improve a pipeline - these evals can label data for fine-tuning LLMs, select high-quality few-shot examples for prompts, or identify failure cases that motivate architectural changes.
What Could Go Wrong? The Three Gulfs
Let’s take the example of an email processing AI product.
The goal is to: extract the sender’s name, summarize the key requests, and categorize the emails.
This might seem simple. But we actually encounter three gulfs, as the famous paper Who Validates the Validators? explains:
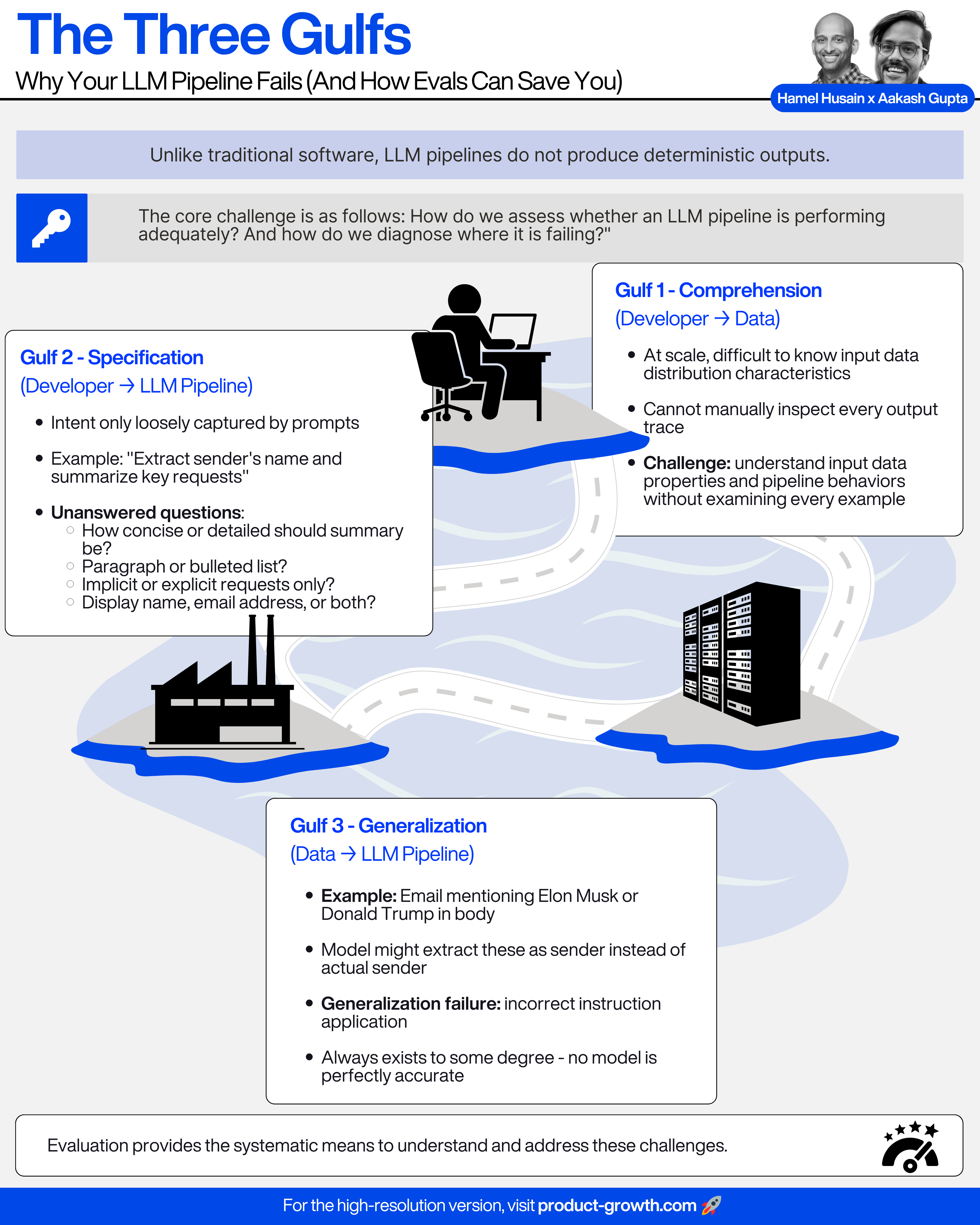
Gulf 1 - Comprehension (Developer → Data)
Thousands of inputs might arrive daily, with diverse formats and varying levels of clarity.
At scale, it is difficult to know the characteristics of this input data distribution, detect errors within it, or identify unusual patterns.
Just as we cannot read every input, we also cannot manually inspect every output trace generated by the pipeline to grasp all the subtle ways it might succeed or fail across the input space.
So the dual challenge is: how can we understand the important properties of our input data, and the spectrum of our pipeline’s behaviors and failures on that data, without examining every single example?
Gulf 2 - Specification (Developer → LLM Pipeline)
Our intent—the task we want the LLM to perform—is often only loosely captured by the prompts you write.
For example, we might write:
Extract the sender’s name and summarize the key requests in this email
At first glance, this sounds specific.
But important questions are left unanswered:
How concise or detailed should the summary be?
Should the summary be a paragraph or a bulleted list?
Should the summary include implicit requests, or only explicit ones?
Should the sender be the display name, the full email address, or both?
The LLM cannot infer these decisions unless we explicitly specify them.
Gulf 3 - Generalization (Data → LLM Pipeline)
Imagine an email that mentions a public figure, like Elon Musk or Donald Trump, within the body text.
The model might mistakenly extract these names as the sender, even though they are unrelated to the actual email metadata.
This is a generalization failure: the model applies the instructions incorrectly because it has not generalized properly across diverse data.
Even when prompts are clear and well-scoped, and even as models get better, this gulf will always exist to some degree, because no model will ever be perfectly accurate on all inputs.
Why Evals are Challenging
Developing effective evaluations for LLM pipelines is hard.
There are at least 4 reasons for this:
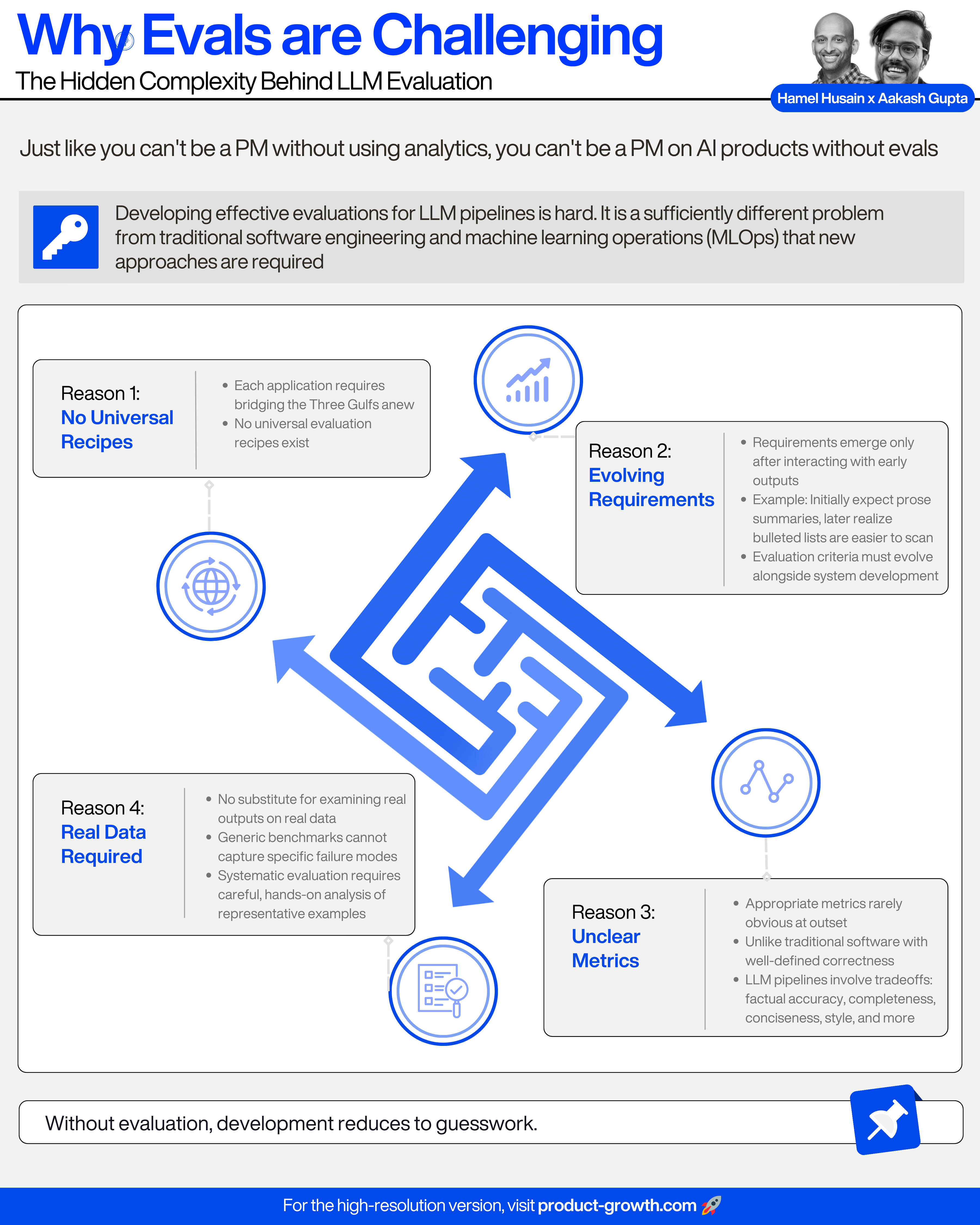
Each application requires bridging the Three Gulfs anew. There are no universal evaluation recipes.
Requirements often emerge only after interacting with early outputs. We might initially expect summaries to be written in prose, but later realize that bulleted lists are easier for users to scan. Evaluation criteria must evolve alongside system development.
Appropriate metrics are rarely obvious at the outset. Unlike traditional software, where correctness is well-defined, LLM pipelines involve tradeoffs: factual accuracy, completeness, conciseness, style, and more.
There is no substitute for examining real outputs on real data. Generic benchmarks cannot capture the specific failure modes of our pipeline. Systematic evaluation requires careful, hands-on analysis of representative examples.
The Solution: The LLM Evaluation Lifecycle
Evaluation provides the systematic means to understand and address these challenges. This is done to through 3 steps:
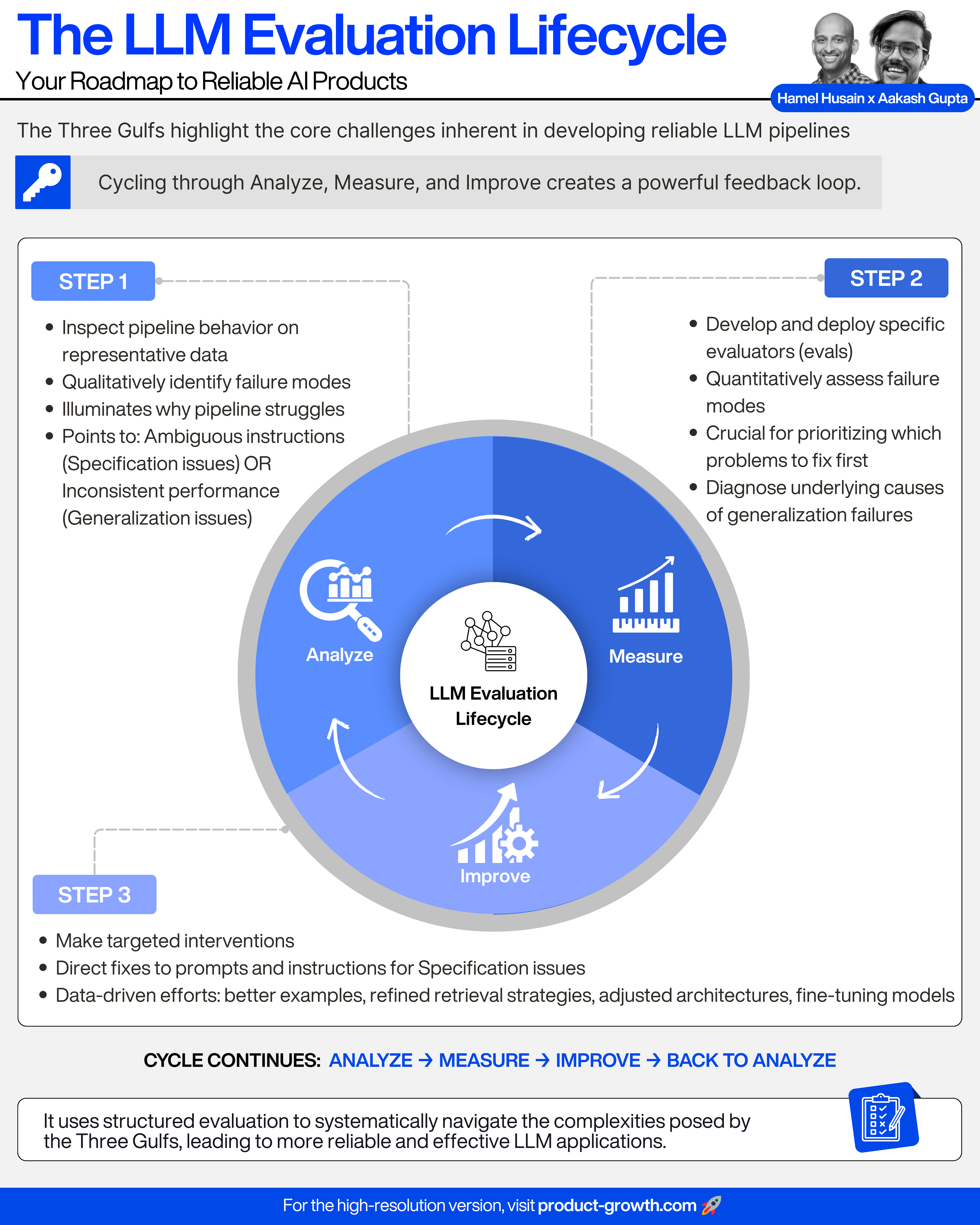
Step 1 - Analyze
Inspect the pipeline’s behavior on representative data to qualitatively identify failure modes.
This critical first step illuminates why the pipeline might be struggling. Failures uncovered often point clearly to:
Ambiguous instructions (Specification issues), or
Inconsistent performance across inputs (Generalization issues)
Understanding their true frequency, impact, and root causes demands quantitative data, hence Step 2…
Step 2 - Measure
Develop and deploy specific evaluators (evals) to quantitatively assess the failure modes.
This data is crucial for prioritizing which problems to fix first and for diagnosing the underlying causes of tricky generalization failures.
Step 3 - Improve
Make targeted interventions.
This includes direct fixes to prompts and instructions addressing Specification issues identified during Analyze.
It also involves data-driven efforts: such as, engineering better examples, refining retrieval strategies, adjusting architectures, or fine-tuning models to enhance generalization.
Cycling through Analyze, Measure, and Improve (and then back to Analyze) uses structured evaluation to systematically navigate the complexities posed by the Three Gulfs, leading to more reliable and effective LLM applications.
We will cover each phase in greater depth in the upcoming sections.
Where We Go From Here
So, that’s your introduction. Now, let’s go a layer deeper…
Eval Basics
🔒 Step 1: Analyze
🔒 Step 2: Measure
🔒 Step 3: Improve
1. The Layer Deeper: Eval Basics
Before we dive further into the practical evaluation lifecycle, let’s understand:
What LLMs can and can't do
How to communicate with them effectively
And the basic types of evaluation metrics out there
LLM Strengths and Weaknesses
We all have experienced LLM’s strengths: they can produce fluent text and generalize to new tasks easily.
But, despite their strengths, LLMs face 4 key limitations that stem from their architecture, training objective, and probabilistic nature:
Algorithmic tasks. They can't reliably execute loops or recursion. A model trained on 3-digit addition often fails on 5-digit sums.
Reliability. Outputs are probabilistic, not deterministic. The same prompt can yield different results.
Prompt sensitivity. Small wording changes can dramatically alter outputs.
Factuality. LLMs optimize for statistical likelihood, not truth. They can confidently assert false information.
Given these strengths and weaknesses, how do we effectively interact with LLMs? The primary method is prompting.
Prompting Fundamentals
What seems obvious to us might be unclear to the LLM.
Precision in our prompt is key.
A well-structured prompt contains 7 key components:

Component 1 - Role and Objective
Clearly define the persona or role the LLM should adopt and its overall goal. This helps set the stage for the desired behavior.
Example:
You are an expert technical writer tasked with explaining complex AI concepts to a non-technical audience.Component 2 - Instructions/Response Rules
Be specific and unambiguous
Use bullet points for multiple instructions
Define what NOT to do
Example:
- Summarize the following research paper abstract.
- The summary must be exactly three sentences long.
- Avoid using technical jargon above a high-school reading level.
- Do not include any personal opinions or interpretations.Component 3 - Context
The relevant background information, data, or text the LLM needs to perform the task.
Component 4 - Examples (Few-Shot Prompting)
One or more examples of desired input-output pairs. Highly effective for guiding format, style, and detail level.
Component 5 - Reasoning Steps (Chain-of-Thought)
For complex problems, instruct the model to "think step by step" or outline a specific reasoning process.
Component 6 - Output Formatting Constraints
Explicitly define the desired structure, format, or constraints for the LLM’s response. This is critical for programmatic use of the output.
Example:
Respond using only JSON format with the following keys: sender_name (string), main_issue (string), and suggested_action_items (array of strings).Component 7 - Delimiters and Structure
Use clear separators (### Instructions ###, triple backticks, XML tags) to distinguish different prompt components.
Precision in prompting is key to bridging the Gulf of Specification.
However, finding the perfect prompt is rarely immediate.
It’s an iterative process.
We’ll write a prompt, test it on various inputs, analyze the outputs (using evaluation techniques we’ll discuss in future sections), identify failure modes, and refine the prompt accordingly.
Note on Outsourcing Prompting
There are many tools that will write prompts for you and optimize them.
It’s important that you avoid these in the beginning stages of development, as writing the prompt forces you to externalize your specification and clarify your thinking.
People who delegate prompt writing to a black box too aggressively struggle to fully understand their failure modes.
After you have some reps with looking at your data, you can introduce these tools (but do so carefully).
An iterative refinement process hinges on having clear ways to judge whether the output is good or bad. This brings us to the concept of evaluation metrics.
Types of Evaluation Metrics
Evaluation metrics provide systematic measurements of LLM pipeline quality. They fall into two categories:
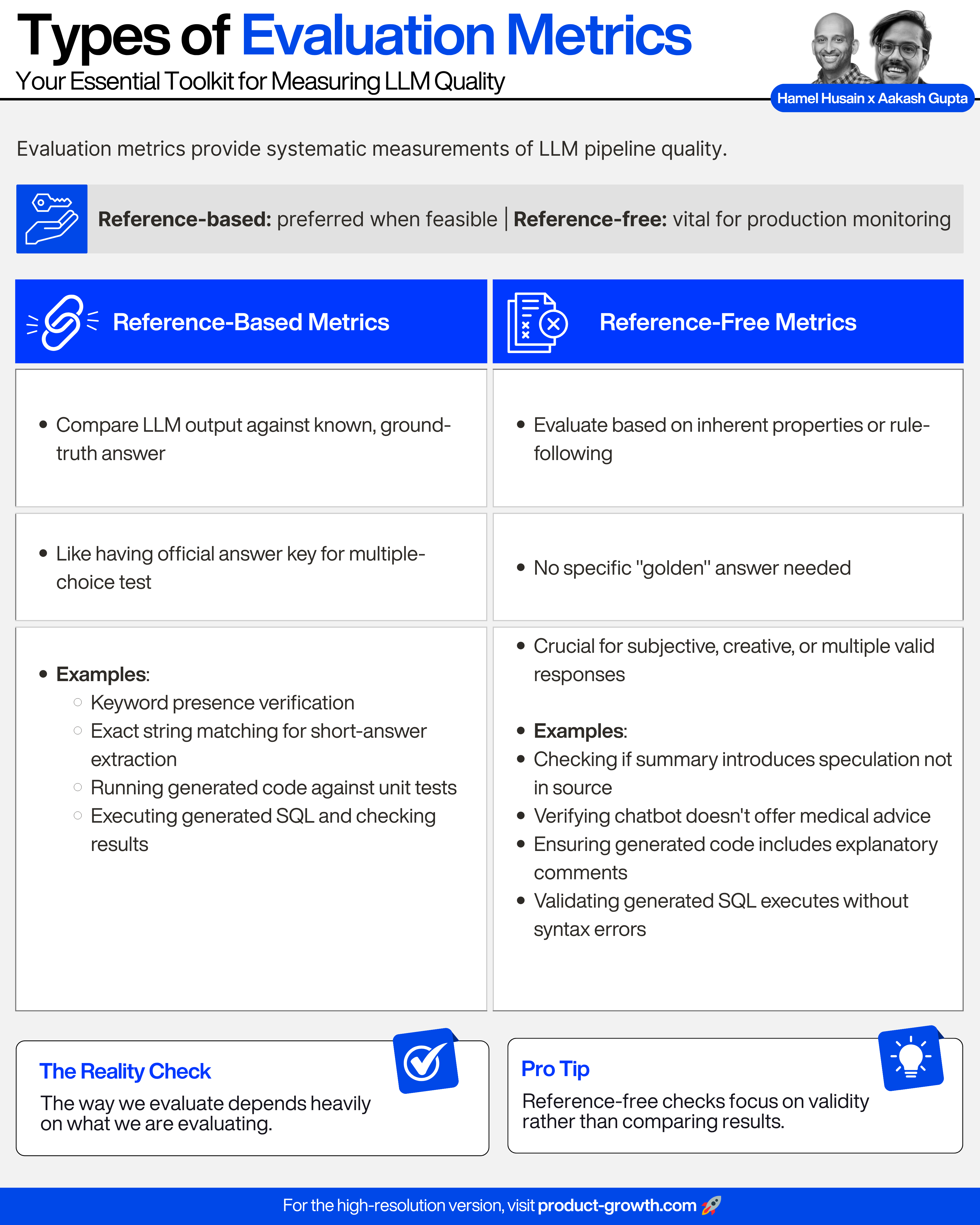
Reference-Based Metrics
These evals compare the LLM’s output against a known, ground-truth answer.
This is much like having an official answer key to grade a multiple-choice test.
Reference-based metrics are often valuable during the development cycle, e.g., as unit tests. Think:
Keyword presence verification
Exact string matching for short-answer extraction
Beyond simple string comparisons, reference-based checks can become more complex.
Sometimes, this involves executing the result and comparing the result with a reference output. For example:
Running generated code against unit tests
Executing generated SQL and checking if the output result or table matches a known correct result or table.
Reference-Free Metrics
Alternatively, reference-free metrics evaluate an LLM’s output based on its inherent properties or whether it follows certain rules, operating without a specific “golden” answer.
This approach becomes crucial when dealing with output that is subjective, creative, or where multiple valid responses can exist.
For example:
Verifying a chatbot doesn't offer medical advice
Ensuring generated code includes explanatory comments
Validating that generated SQL executes without syntax errors
Checking if a summary introduces speculation not in the source
These examples illustrate how reference-free qualities are highly application-specific.
Reference-free checks focus on validity rather than comparing results.
The distinction matters
Reference-based metrics are preferred when feasible because they're much cheaper to maintain and verify.
Simple assertions and reference-based checks require minimal overhead, while LLM-as-Judge evaluators need 100+ labeled examples and ongoing maintenance.
Focus automated evaluators on failures that persist after fixing your prompts.
Many teams build complex evaluation infrastructure for preferences they never actually specified, like wanting short responses or specific formatting. Fix these obvious specification gaps first.
Consider the cost hierarchy:
Start with cheap code-based checks (regex, structural validation, execution tests)
Reserve expensive LLM-as-Judge evaluators for persistent generalization failures that can't be captured by simple rules.
The way we evaluate depends heavily on what we are evaluating—and the cost of maintaining that evaluation over time.
Foundation Models vs Application-Centric Evals
Foundation Model Evals (like MMLU, HELM, GSM8k) assess general capabilities and knowledge of base LLMs. Think of them as "standardized tests"—useful for initial model selection but insufficient for your specific application.
Application Evals assess whether your specific pipeline performs successfully on your specific task using your realistic data. These are your primary focus because:
Foundation models undergo opaque alignment processes
General post-training may not match your application's requirements
You need metrics capturing your specific quality criteria
Be extremely skeptical of generic metrics for your application.
In most cases, they're a distraction.
The quickest smell that an evaluation has gone off the rails is seeing a dashboard packed with generic metrics like "hallucination_score," "helpfulness_score," "conciseness_score."
Since application-specific evaluations often involve criteria beyond simple right/wrong answers, we need methods to systematically capture these judgments. How do we actually generate these evaluation signals?
Eliciting Labels for Metric Computation
How do we actually generate the scores or labels needed to compute our metrics?
This question is especially pertinent for reference-free metrics, where there is no golden answer key. How can we systematically judge qualities defined by our application, like "helpfulness" or "appropriateness"?
We recommend starting with binary Pass/Fail evaluations in most cases, as we'll explore in detail later. Binary evaluations force clearer thinking and more consistent labeling, while Likert scales introduce significant challenges: the difference between adjacent points (like 3 vs 4) is subjective and inconsistent across annotators, and annotators often default to middle values to avoid making hard decisions.
With this preference for binary judgments in mind, three general approaches are used:
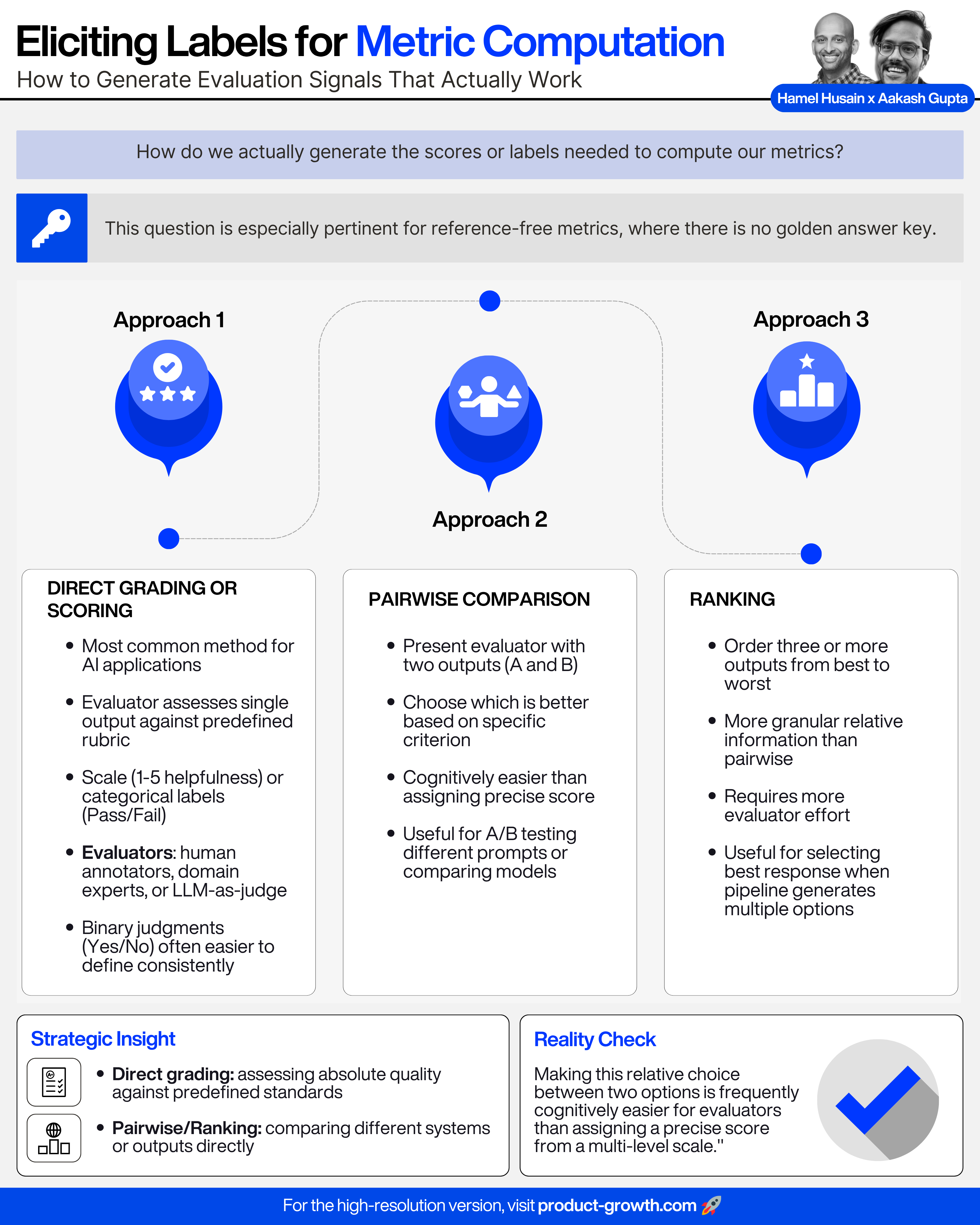
Approach 1 - Direct Grading or Scoring
The most common method of evaluations for AI applications is Direct Grading or Scoring. Here, an evaluator assesses a single output against a predefined rubric.
This rubric might use a scale (e.g., 1-5 helpfulness) or categorical labels (e.g., Pass/Fail, Tone: Formal/Informal/Casual).
Evaluators can be human annotators, domain experts, or a well-prompted "LLM-as-judge," or an LLM that has been prompted to assess outputs according to the rubric.
Obtaining reliable direct grades demands extremely clear, unambiguous definitions for every possible score or label. Defining distinct, objective criteria for each point on a 1-5 scale can be surprisingly difficult.
For this reason, simpler binary judgments (like Yes/No for "Is this summary faithful to the source?") are often easier to define consistently and are our recommended starting point.
Binary decisions are also faster to make during error analysis—you don't waste time debating whether something is a 3 or 4.
Direct grading is most useful when our primary goal is assessing the absolute quality of a single pipeline's output against our specific, predefined standards.
Approach 2 - Pairwise Comparison
Pairwise comparison presents an evaluator with two outputs (A and B) generated for the same input prompt. The evaluator must then choose which output is better based on a specific, clearly defined criterion or rubric.
While this still requires unambiguous comparison criteria, making this relative choice between two options is frequently cognitively easier for evaluators than assigning a precise score from a multi-level scale.
Approach 3 - Ranking
Evaluators order three or more outputs generated for the same input from best to worst, according to the same clearly defined quality dimension specified in the comparison rubric.
Ranking provides more granular relative information than pairwise comparison, though it typically requires more evaluator effort.
These relative judgment methods are particularly useful when our main goal is to compare different systems or outputs directly. We might use them for A/B testing different prompts, comparing candidate models, or selecting the best response when our pipeline generates multiple options for a single input.
For tracking gradual improvements, consider measuring specific sub-components with their own binary checks rather than using scales.
For example, instead of rating factual accuracy 1-5, track "4 out of 5 expected facts included" as separate binary checks. This preserves the ability to measure progress while maintaining clear, objective criteria.
The Layer Deeper - Step 1: Analyze
The process of developing robust evaluations for LLM applications is inherently iterative.
This section provides a detailed methodology for the Analyze portion—specifically focusing on how we systematically surface failure modes.
Keep reading with a 7-day free trial
Subscribe to Product Growth to keep reading this post and get 7 days of free access to the full post archives.
 | A guest post by
|